内存
1. 代码内存分布
| 内存空间 | 存放内容 | 读写权限 |
|---|---|---|
| 内核空间 | 操作系统运行的内存空间。栈,堆。。齐全 | 应用程序不能直接操作 |
| 栈 | 函数局部变量,形参 | 读/写 |
| 堆 | new/malloc申请空间 |
读/写 |
| 全局的数据空间 | 全局变量,static变量。包括初始化化的(data),未初始化的(bss)。 |
读写 |
| 只读数据段 | "github"等字符串常量 |
读 |
| 代码段 | 程序代码最终的指令集 | 读 |
2. 内存泄露/栈溢出
- 内存泄露: 堆使用了,没清空,内存大量浪费
- 栈溢出: 使劲增加局部变量,栈用完了
3. 字符存储编码
- ASCII 码: 使用指定的7 位或8 位二进制数组合来表示128 或256 种可能的字符。
- BCD码: (Binary-Coded Decimal)亦称二进码十进数或二-十进制代码。用4位二进制数来表示1个十进制数中的0~9这10个数码。
- 内码: 指汉字系统中使用的二进制字符编码。
4. 字节对齐
4.1. 介绍
4.1.1. 概念
内存空间按照字节划分,在访问特定类型变量时经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序一个接一个地存放,这就是对齐。
4.1.2. 原因
- 不同硬件平台对存储空间的处理上存在很大的不同。某些平台对特定类型的数据只能从特定地址开始存取,不能任意存放数据。
- 不按照平台要求对数据存放进行对齐,会带来存取效率上的损失。例如:一个32位的数据没有存放在4字节整除的内存地址处,那么处理器就需要2个总线周期对其进行访问。
- 说白了就是为了CPU读写数据时,统一规则,能一大块一大块的拿,节约时间。
4.2. 字节对齐计算
4.2.1. 字节对齐值
[!note]
- 数据类型「自身对齐值」:char型数据自身对齐值为1字节,short型数据为2字节,int/float型为4字节,double型为8字节。
- 结构体或类的「自身对齐值」:
max(成员中自身对齐值)- 指定对齐值:
#pragma pack (对齐值)- 结构体和类的「有效对齐值」:
min{类,结构体自身对齐值,当前指定的pack值}。- 数据成员的「有效对齐值」:
min{成员自身对齐值,当前指定的pack值}- 默认对齐值 :
64位,8字节;32位,4字节。
4.2.2. 字节对齐准则
[!warning|style:flat]
- 有效对齐值
N最终决定数据存放地址方式。表示「对齐在N上」,即存放的起始地址满足起始地址 % N == 0- 数据结构中的数据变量都是按定义的先后顺序存放。第一个数据变量的起始地址就是数据结构的起始地址。 类,结构体的成员变量要对齐存放
- 结构体本身也要根据自身的「有效对齐值」圆整, 即结构体成员变量占用总长度为结构体「有效对齐值」的整数倍,不足也要补足。
4.2.3. 储存字节计算
#pragma pack()
struct TestA{
char ch;
int i;
double d;
const char cch;
};
struct TestB{
char chb;
struct TestA a;
int ib;
};
#pragma pack() // 缺省,恢复默认的对齐字节
int main(void){
struct TestB b;
printf("amount: %d\n",sizeof(b));
printf("b.a: %d\n",
(unsigned int)(void*)&b.a - (unsigned int)(void*)&b);
printf("b.a.ch: %d\n",
(unsigned int)(void*)&b.a.ch - (unsigned int)(void*)&b);
printf("b.a.i: %d\n",
(unsigned int)(void*)&b.a.i - (unsigned int)(void*)&b);
printf("b.a.d: %d\n",
(unsigned int)(void*)&b.a.d - (unsigned int)(void*)&b);
printf("b.a.cch: %d\n",
(unsigned int)(void*)&b.a.cch - (unsigned int)(void*)&b);
printf("b.ib: %d\n",
(unsigned int)(void*)&b.ib - (unsigned int)(void*)&b);
return 0;
}
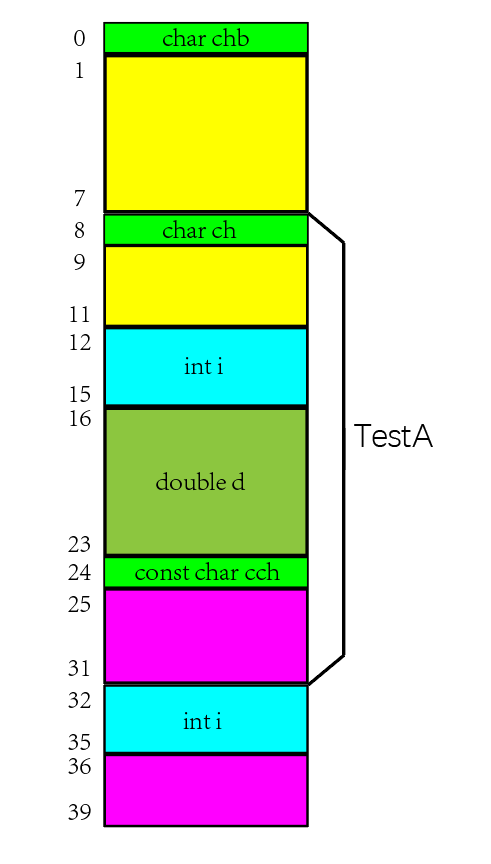
对TestB的储存结构进行说明:
64位系统,默认对齐字节8;2.
char chb:char的自身对齐值min{1,8},所以存储地址首地址0 % 1 == 0成立。3.
TestA a:double d;字节数最大,所以其「自身对齐值」为8,有效对齐值为min{8,8},存储地址首地址 8 % 8 == 0 成立。===开始对
TestA a内部字节8 ~ 31进行划分。===1.
char ch;:就按照TestA a首地址往下存。2.
int i;:int的自身对齐值min{4,8},所以存储地址首地址12 % 4 == 0成立。3.
double d;:double的自身对齐值min{8,8},所以存储地址首地址16 % 8 == 0成立。4.
const char cch;:char的自身对齐值min{1,8},所以存储地址首地址24 % 1 == 0成立。5. 由于
TestA a的「有效对齐值」为 min(8,8) ,根据「圆整准则」TestA a 的大小必须为 n*8 ,所以最后的 25 ~ 31 为编译器填充。 ===对
TestB进行最后圆整收尾===1. 对于
TestB而言成员最大的对齐值是TestA a ,「有效对齐值」为 min(8,8) ,所以TestB 的大小必须为 n*8 ,最后进行了 36 ~ 39 的填充。
4.2.4. # pragma pack()
[!note]
# pragma pack(对齐值):可以重新定义默认的对齐字节值,计算方法就是3.中的默认值替换掉,然后同上计算。 对齐值只能为 。# pragma pack(): 缺省,表示使用默认。# pragma pack(push): 将当前对齐字节值保存# pragma pack(pop): 将保存的对齐字节值弹出
4.3. 字节对齐的隐患
4.3.1. 问题
// 案列一
int main(void){
unsigned int i = 0x12345678;
unsigned char *p = (unsigned char *)&i;
*p = 0x00;
unsigned short *p1 = (unsigned short *)(p+1);
return 0;
}
// 案列二
void Func(struct B *p2){
//Code
}
[!note|style:flat] 案列一:
p1访问内存数值时,由于指向为奇数,对于32位会降低速度,对于特殊CPU则会异常。
案列二:p2如果是跨CPU访问,对齐要求不同,也会导致异常。
4.3.2. 解决方案
[!tip|style:flat] 对于案列二,可以选择修改对齐方式,然后重新赋值,让编译器解决。
#pragma pack(对齐值) void Func(struct B *p){ struct B tData; memmove(&tData, p, sizeof(struct B)); //此后可安全访问tData.a,因为编译器已将tData分配在正确的起始地址上 }规划好字节排序:
- 同一类型尽量放一起
- 默认对齐字节整数倍大小的紧凑放最前
- 接着放能够凑成默认对齐字节大小的
- 不够默认对齐字节的放最后,并添加几个填充字符。
typedef struct tag_T_MSG{ // 默认对齐字节大小 int ParaA; int ParaB; // 凑默认对齐字节大小 short ParaC; char ParaD; //填充字节 char Pad; }T_MSG;
4.4. 默认对齐字节的由来
4.4.1. 内存的结构
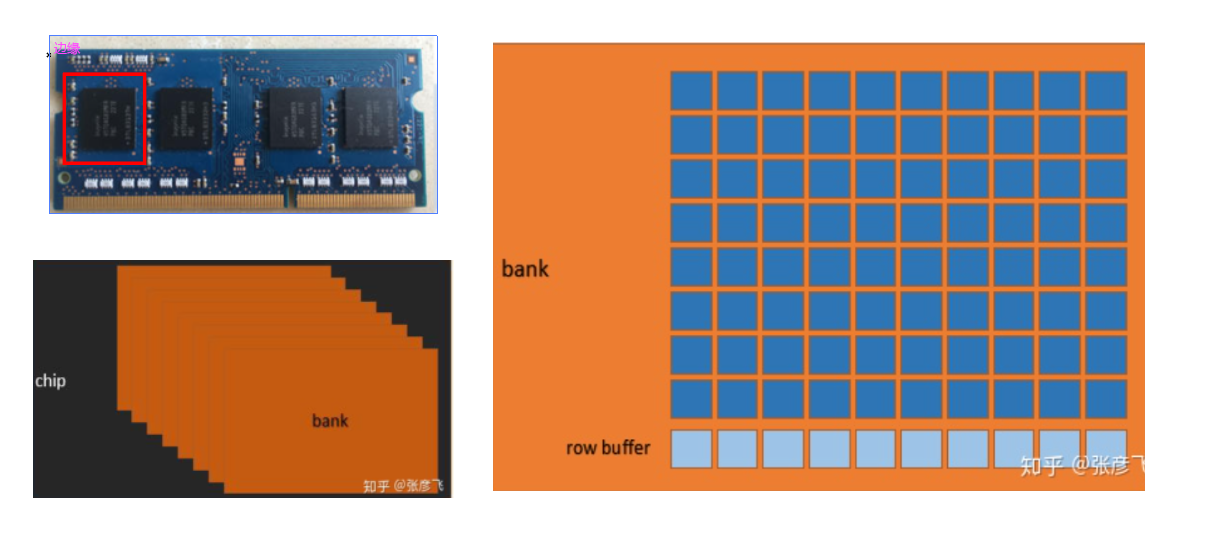
一个内存是由若干个「黑色的内存颗粒」构成;一个内存颗粒叫做一个「chip」;每个「chip」内部,是由8个「bank」组成的;每一个「bank」是一个二维平面上的矩阵,每一个元素中都是保存了1 byte,也就是8 bit。
4.4.2. 内存地址
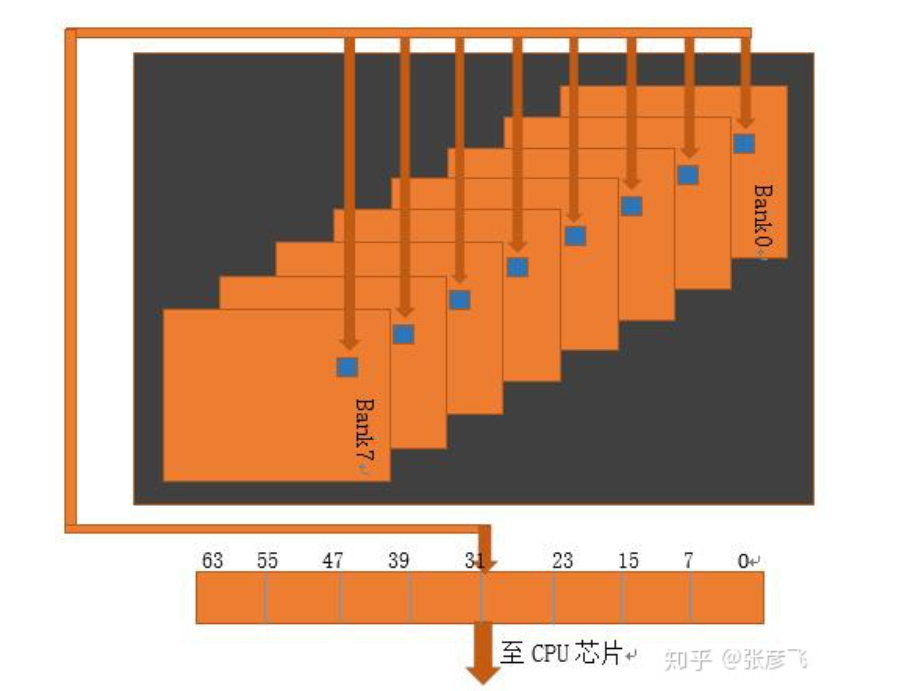
内存地址编号:
一个地址编号对应一个字节,对于地址0x0000-0x0007地址,是在第一个「chip」上,是由重叠的8个「bank」相同位置上的元素从bank0 ~ bank7进行编号,8个「bank」是可以并行工作,加快读写速度。
8个「bank」:
64位cpu对内存的一次操作只能操作8 byte,因为64位cpu的寄存器是64位的,只能放8 * 8 bit的值。
4.4.3. 字节对齐默认值
[!note|style:flat]
64位的cpu,默认对齐字节为8, 这就能保证,小于等于8字节的数据存储位置,是cpu能一次操作就能成功获取完毕的。
假如: 你指定要获取的是0x0005 ~ 0x0009的数据:内存只好先工作一次把0x0000-0x0007取出来,然后再把0x0008-0x0000f取出来,最后再把两次的结果合并,把最终结果返回。
同理32位的cpu默认对齐字节位4,因为32位cpu的寄存器是32位的。
5. 内存碎片
参考博客:
5.1. 定义
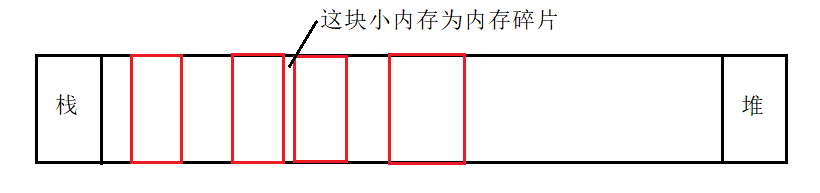
[!note|style:flat] 内存碎片(碎片的内存):一个系统中所有不可用的空闲内存,这些空闲内存小且以不连续方式出现在不同的位置,分为外碎片和内碎片。
- 外碎片: 还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域。
- 内碎片: 已经被分配出去(能明确指出属于哪个进程)却不能被利用的内存空间
5.2. 产生原因
外碎片的产生
原因: 频繁的「分配」与「回收」物理页面,这会导致大量的、连续且小的页面块夹杂在已分配的页面中间,就会产生外部碎片。

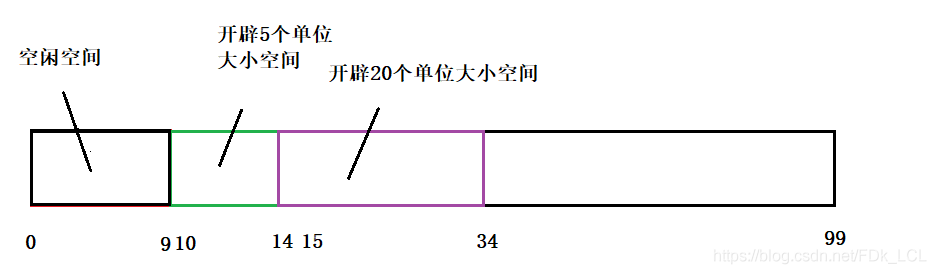
内碎片的产生
原因: 「字节对齐」时,会导致空闲区域的产生。详情见「字节对齐」
6. 类/结构体的内存分布
6.1. 类
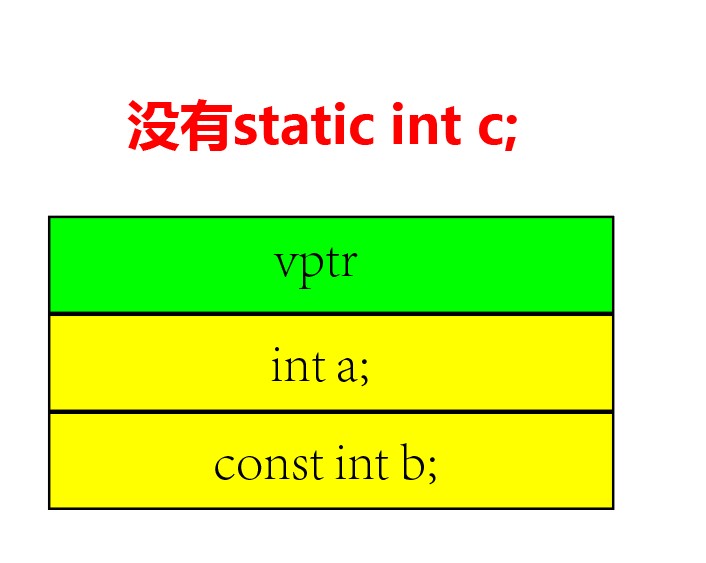
一个类在内存中的组成:
- 若有
virtual方法:第一个为vptr,所占字节数根据操作系统来:64位:8 byte,32位:4 byte。 - 非
static变量 ,static变量在静态区。 -
const变量也在里面,虽然编译器会对常量进行优化放到常量表,但是根还在这儿。 - 对象变量指向第一个内存位置的地址
- 属性存放顺序与定义顺序一样
6.2. 子类

[!note]
- 父类的若有
vptr就放第一个,- 接着是父类的非static属性
- 最后放子类的属性
- 防止多重继承,出现属性多次定义,继承时,使用 virtual 进行修饰。
6.3. 结构体
与类一样。唯一不同点,就是没有vptr。
6.4. 字节计算
- 类:
sizeof(vptr)+5.2的结果;sizeof(vptr)由操作系统定,64位,8 byte;32位,4 byte - 结构体:
5.2的结果
7. 对象与类
| 类型 | 描述 | 储存 |
|---|---|---|
| 类 | 模板,包括属性和行为 | 无 |
| 对象 | 类的实例化,主要是数据的集合 | 主要只储存了属性,储存位置看具体情况 ; 函数放代码段,所有对象通用 |
[!warning|style:flat] 类的概念没有占用内存,但是
sizeof(类名)是有值的,等于sizeof(实列)计算结果。
8. 代码地址
- 运行时地址起始位置:它芯片公司指定的一开始运行代码的位置。
- 运行地址: 就在从运行时地址起始位置(包括起始位置)往后排都是运行时地址。(程序代码被搬过来执行)
- 链接地址起始位置:链接脚本设定,这个位置在程序链接之后,就会确定下来。(用来计算偏移量的伪地址,之后重定向)
- 链接地址: 就是从链接地址起始位置(包括起始位置)往后排都是链接地址。(类似汇编地址)
- 加载地址: 从flash的那个地方开始读取程序,加载内存中去。
- 存储地址: 程序存储在哪儿的。
9. --cpy
#include <string.h>
void *memcpy(void * __dest,const void *__src, size_t n);
void *memmove (void * __dest, const void *__src, size_t n);
char *strncpy(char * __dest,const char *__src, size_t n);
char *strcpy(char * __dest,const char *__src);
| 函数 | 描述 | 结束 | 重叠问题 |
|---|---|---|---|
memcpy |
可以复制任意内容 | 复制n个,停止 |
未定义 |
memmove |
可以复制任意内容 | 复制n个,停止 |
保证dest没问题,src可能会乱掉 |
strcpy |
复制字符串 | 到\0停止 |
未定义 |
strncpy |
复制字符串 | 复制n个,停止 |
未定义 |
1. memcpy 与 strncpy
[!note|style:flat] 当
n大于了src长度时:
memcpy:src后面的内存接着拷贝,管他是啥。strncpy:采用\0进行补全
2. strcpy 与 strncpy
[!note|style:flat]
strcpy: 拷贝到\0结束拷贝strncpy:拷贝到n结束,超过了用\0进行补全,不会主动添加\0
void *memmove(void *dest, const void *src, size_t count)
{
char *tmp;
const char *s;
// 目标起始地址 小于等于 源头的起始地址,从头开始 ++ 进行拷贝,dest 的值就是 原来的 src 的值,重叠部分的 src 值出错
if (dest <= src) {
tmp = dest;
s = src;
while (count--)
*tmp++ = *s++;
}
// 目标起始地址 大于 源头的起始地址,从尾部开始 -- 进行拷贝,dest 的值就是 原来的 src 的值,重叠部分的 src 值出错
else
{
tmp = dest;
tmp += count;
s = src;
s += count;
while (count--)
*--tmp = *--s;
}
return dest;
}
void *memcpy(void *dest, const void *src, size_t count)
{
char *tmp = dest;
const char *s = src;
while (count--)
*tmp++ = *s++;
return dest;
}
char * strcpy(char *dst,const char *src)
{
assert(dst != NULL && src != NULL);
char *ret = dst;
while ((*dst++=*src++)!='\0');
return ret;
char * __cdecl strncpy (char * dest,constchar * source,size_t count)
{
char *start = dest;
while (count && (*dest++ = *source++)) /* copy string */
count--;
if (count) /* pad out with zeroes */
while (--count)
*dest++ ='\0';
return(start);
}
[!note|style:flat] 从源码中可以查库,四个拷贝函数的底层都是通过
char进行拷贝的。
10. 类创建的限制
10.1. 限制在堆
[!tip]
- 方式:将析构函数设置为私有。
- 原因:
C++是静态绑定语言,编译器在为类对象分配栈空间时,会先检查类的「析构函数」的访问性。若析构函数不可访问,则不能在栈上创建对象。
class Test{
private:
~Test(){};
public:
};
10.2. 限制在栈
[!tip] 方式:将
new和delete重载为私有。 原因:在堆上生成对象,使用new关键词操作,其过程分为两阶段:第一阶段,使用new在堆上寻找可用内存,分配给对象;第二阶段,调用构造函数生成对象。将new操作设置为私有,那么第一阶段就无法完成,就不能够再堆上生成对象。
class Test{
private:
void* operator new(std::size_t size)
{
return std::malloc(size);
}
void operator delete(void* ptr)
{
std::free(ptr);
}
public:
};
10.3. 单例模式
在内存里,只有一个对象。
class Test{
private:
Test(){};
public:
static Test& getInstance(){
static Test instance;
return instance;
}
};