机器学习-神经网络
模型:
{z=wTx+by^=σ(z)(1.1)
其中x为输入量,y^预测量,σ()激活函数。
逻辑回归主要用于二分类问题的拟合:0≤y^=P(y=1∣x)≤1,σ(z)如图:
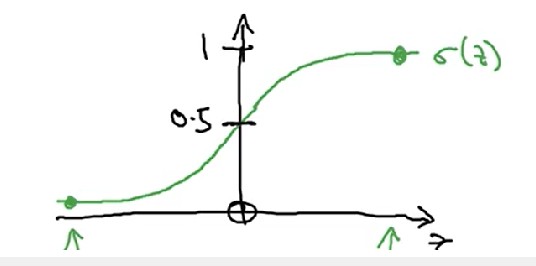
问题:
对于模型(1.1),需要通过一系列的样本(x,y={0,1}),求解出系数w,b。
求解:
转为最优化问题,然后对未知系数进行求解。
-
作用:
用于衡量单个样本,在进行模型预测后 y 与 y^ 之间的差距。
-
二分问题的损失函数
L(y,y^)=−(ylny^+(1−y)ln(1−y^))(2.1a)
-
拟合问题的一般损失函数
L(y,y^)=∣∣y−y^∣∣2
注意:
L()函数应该是凸集,防止在寻优的过程中出现多个局部最优解。(y=x2就是典型的凸集)
用于对全部的样本的预测结果进行评估。也就是最终寻优的目标函数。
J(w,b)=m1i=1∑mL(y(i),y^(i))(2.2)
对于目标函数J使用梯度下降法进行寻优,迭代更新(w,b),最终得到使得J最小的变量值(w,b)就是模型(1.1)的解。也就完成了对于模型的训练。
⎩⎨⎧w=w−αdwdJb=b−αdbdJ(2.3)
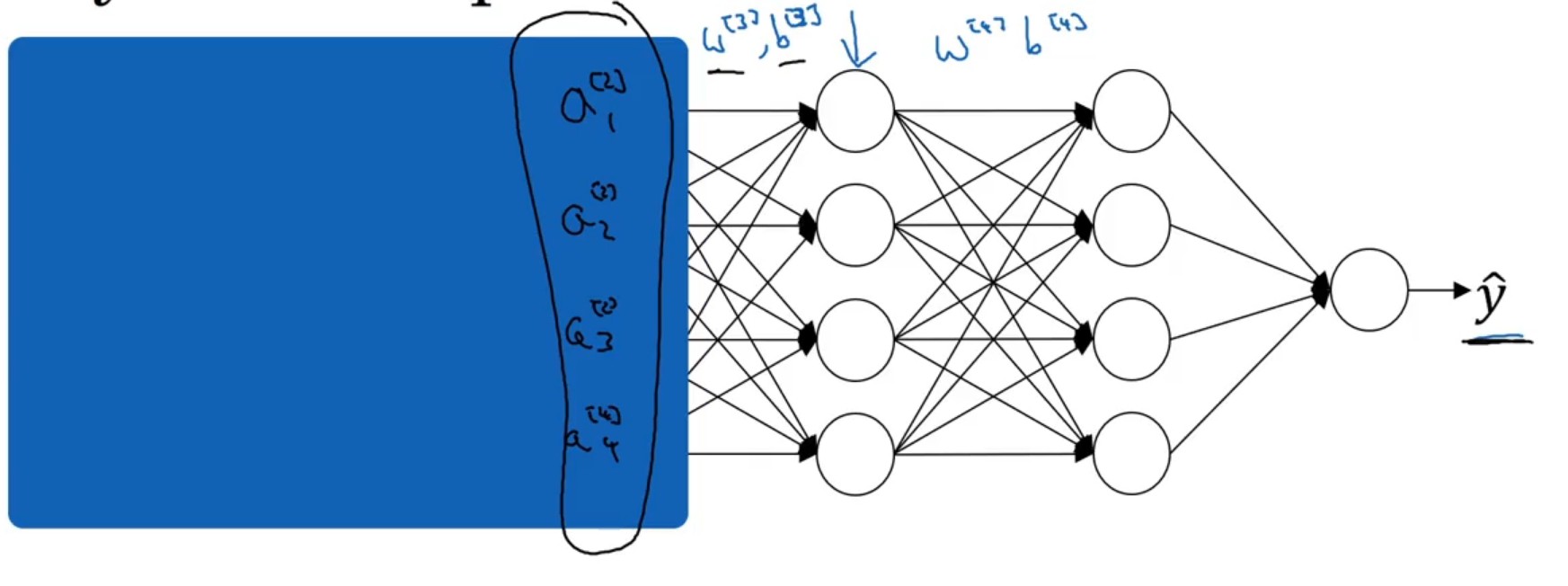
BP神经网络层只有三层:Input layer,Hiden layer,Output layer;
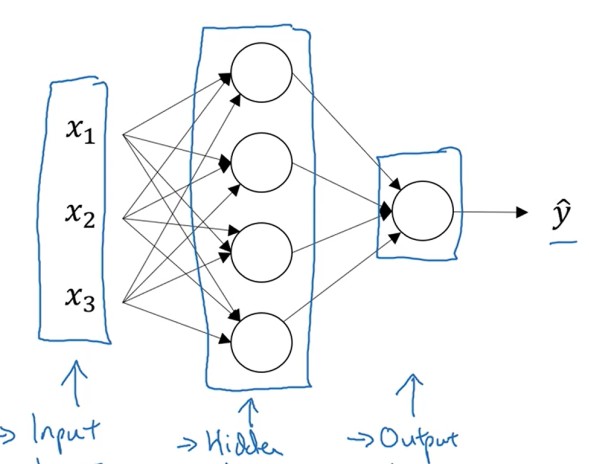
节点的计算与逻辑回归相似。
{z[i]=(w[i])Tx+b[i]a[i]=σ(z[i])(2.4)
-
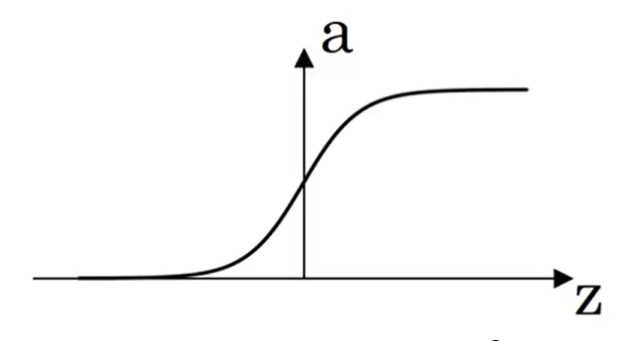
sigmoid
二分问题,输出节点必使用sigmoid。
{a=1+e−z1dzda=a(1−a)(2.5)
-
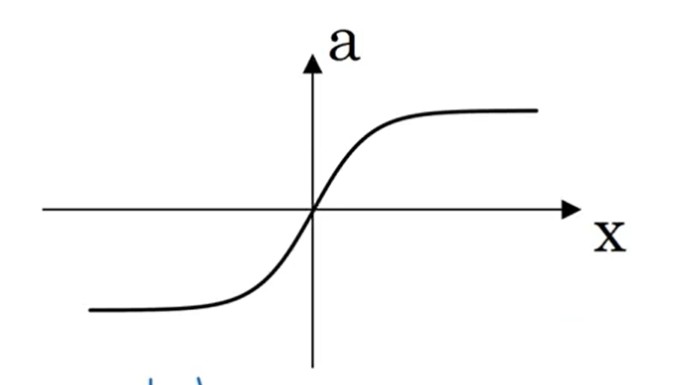
tanh (tansig)
MATLAB中的 tansig 激活函数,就是tanh的化解形式。
{a=ez+e−zez−e−zdzda=1−a2(2.6)
-
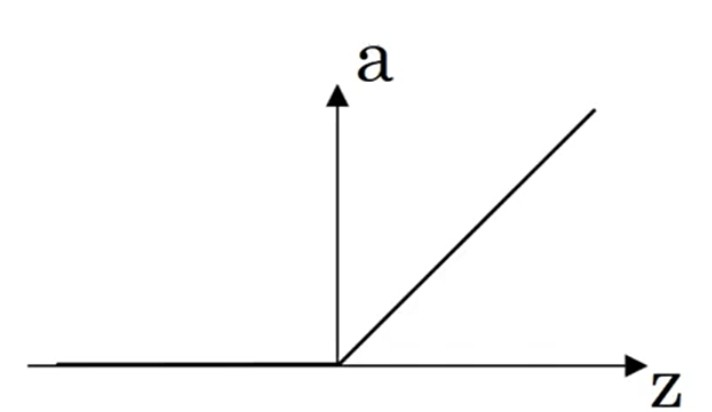
ReLU
拟合问题,输出节点必使用ReLU
{a=max(0,z)dzda=if(z≥0):1,0(2.7)
-
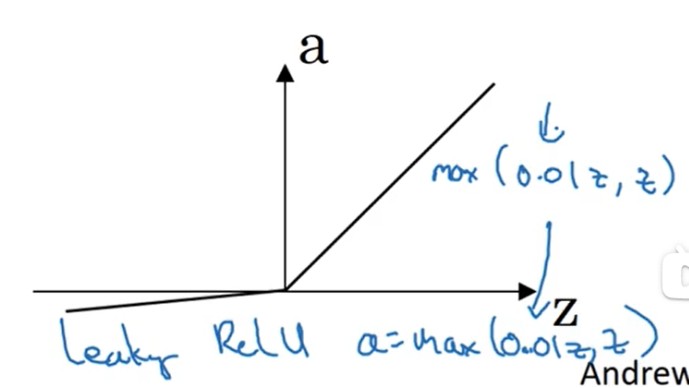
Leaking ReLU
{a=max(0.01z,z)dzda=if(z≥0):1,0.01(2.7)
-
正向传播

-
反向传播
dz[2]=a[2]−ydW[2]=dz[2]a[1]Tdb[2]=dz[2]dz[1]=W[2]Tdz[2]∗g[1]′(z[1])dW[1]=dz[1]xTdb[1]=dz[1](2.8)
注意:
- 代表的是:numpy.multiply()
- 反向传播公式只适用于二分问题
- 隐含层节点的初始化值应当不同;否则会导致节点的计算结果一样,多节点无意义。
- W的初始化值应当较小;使得激活函数落在斜率大的地方,梯度下降法收敛快。
对于神经网络模型而言,决定最终神经网络模型性能的系数是w和b,其余可调的系数均为超参数。
在模型生成的过程中,根据样本数据起到的作用,进行集合类型的划分。
- 训练集(Train Set): 用于模型的训练。
- 开发集(Dev Set): 用于对训练中的模型进行测试。
- 测试集(Test Set): 用于对最终的模型进行测试。
注意:训练集和开发集的数据应当来自于同一组样本。
-
偏差
模型在样本上,输入与输出之间的误差,即模型本身的精确度。反应在训练集上。
-
方差
模型预测结果与输出期望之间的误差,即模型的稳定性。反应在开发集与训练集上。
-
关系
- 低偏差|低方差:最想要的结果。
- 低偏差|高方差:过拟合 (overfitting),对测试集和开发集拟合能力差。
- 高偏差:欠拟合 (underfitting),模型拟合得很差。
过拟合
- 简化模型复杂度
- L2正则化和Dropout
- 增加样本数量
欠拟合
- 使用更复杂的神经网络模型
- 更换优化方法
- 增加迭代训练次数
作用:降低模型的复杂度,从而防止模型的过拟合问题。
在梯度下降法中,对于目标函数J添加一个正则项:
J(w,b)=m1i=1∑mL(y(i),y^(i))+2mλl∑∣∣w[l]∣∣22(2.1)
这就会导致更新每一层的w系数时:
wL2[l]=w[l]−α(dw[l]+mλw[l])(2.2)
增大系数λ便会使得w[l]的值减小;当一个神经元节点的w≈0时,该神经元节点便在模型中失效。
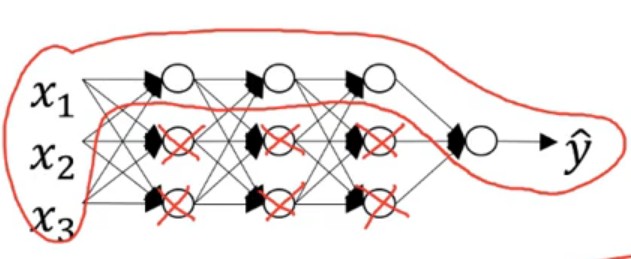
减少一次训练样本中的节点,防止过拟合。不依赖一个特性,将权重值分散。
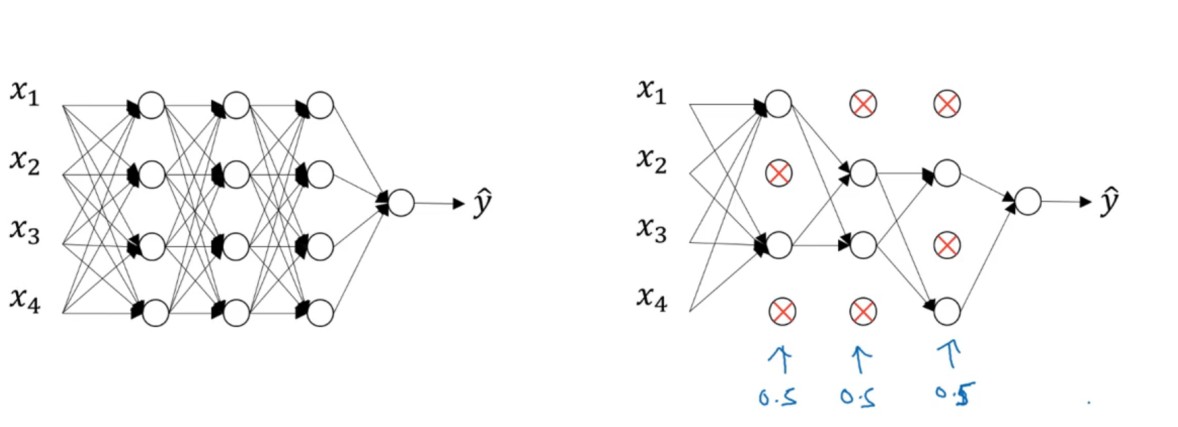
实现:将a[l]中的某些元素置为0。(inverted dropout)
注意:
- 经过处理后的J无明确的意义
- 该方法主要用于图像识别
对于样本首先进行归一化处理,然后才能使用。
正向:
Xnorm=Xmax−Xmin2(X−Xmin)−1(3.1)
反向:
X=(Xnorm+1)2Xmax−Xmin+Xmin(3.2)
正向:
Xnorm=Xmax−XminX−Xmin
反向:
X=Xnorm(Xmax−Xmin)+Xmin(3.2)
对于深度的神经网络;
- 当w > 1时,从输入层到输出层,输出值将会很大
- 当w < 1时,从输入层到输出层,输出值将会很小
为了避免这些问题,需要对w值进行合理的初始化。即 var(w[l])=n[l]2,E(w[l])=0
w[l]=numpy.multiply(randn(),n[l]2)(4.1)
其中n代表一个神经元节点输入的个数。
vt=βvt−1+(1−β)θt(5.1)
对于vt可以认为是前1−β1个v值的平均值。
在初始时刻,使用指数加权平均,会导致估计值偏差较大。在后期时刻,偏差就基本近似。所以可以对初期的估计值进行修正。
vt=1−βtvt(5.2)
将样本数据中的训练集再划分为多个子集,再依次利用这些子集进行模型训练。
- 子集的样本量:m≤200
- 子集的个数:2i
- mini batch 训练过程中,J的变化是振荡。
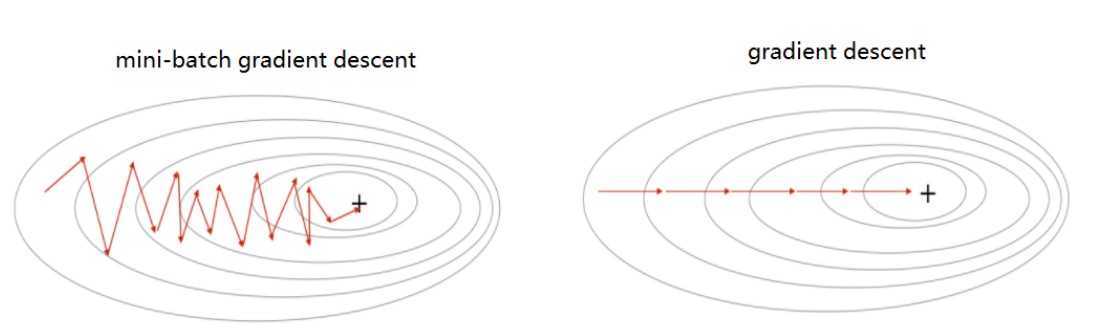
对于梯度下降法,Mini Batch的(w,b) 的变化如上图所示,是振荡的,向着最优解靠近。在这种情形下,使用梯度下降法时,学习率α不能太大。
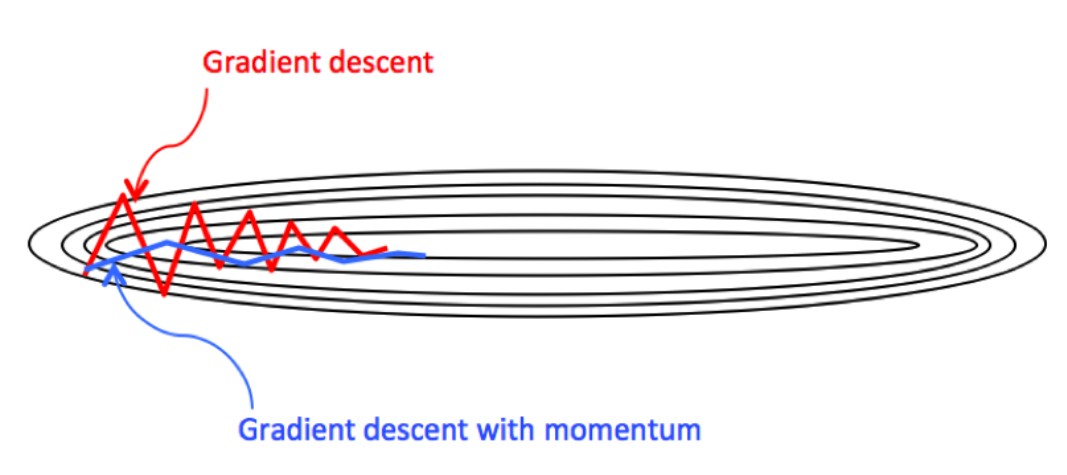
对变量(w,b)使用 指数加权平均 降低振荡,使得收敛过程更加的平缓。这样就能加大学习率α,减少迭代次数。
vdw=βvdw+(1−β)dwvdb=βvdb+(1−β)dbw=w−αvdw,b=b−αvdb(6.1)
在降低振荡振幅的基础上,还要缩短纵轴的波动,延长横轴的长度。
SdwSdbwb=βSdw+(1−β)(dw.∗dw)=βSdb+(1−β)(db.∗db)=w−αSdw+ϵdw=b−αSdb+ϵdw(6.2)
其中ϵ是一个很小的值,防止S为0,造成运算异常。
对RMSprop法和动量法的整合,改进。
vdwvdbSdwSdbvdwcorrevdbcorreSdwcorreSdbcorrewbβ1β2=β1vdw+(1−β1)dw=β1vdb+(1−β1)db=β2Sdw+(1−β2)(dw.∗dw)=β2Sdb+(1−β2)(db.∗db)=1−β1tvdw=1−β1tvdb=1−β2tSdw=1−β2tSdb=w−αSdwcorre+ϵvdwcorre=b−αSdbcorre+ϵvdbcorre=0.9=0.999(6.3)
在训练的前期使用较大的学习率,在快要收敛时,使用较小的学习率。
α=1+delayRate∗epochNum1α0(7.1)
对一个batch样本在一个神经元节点中的所有zj[i]进行Z标准化处理,然后再带入激活函数,求解aj[i]。
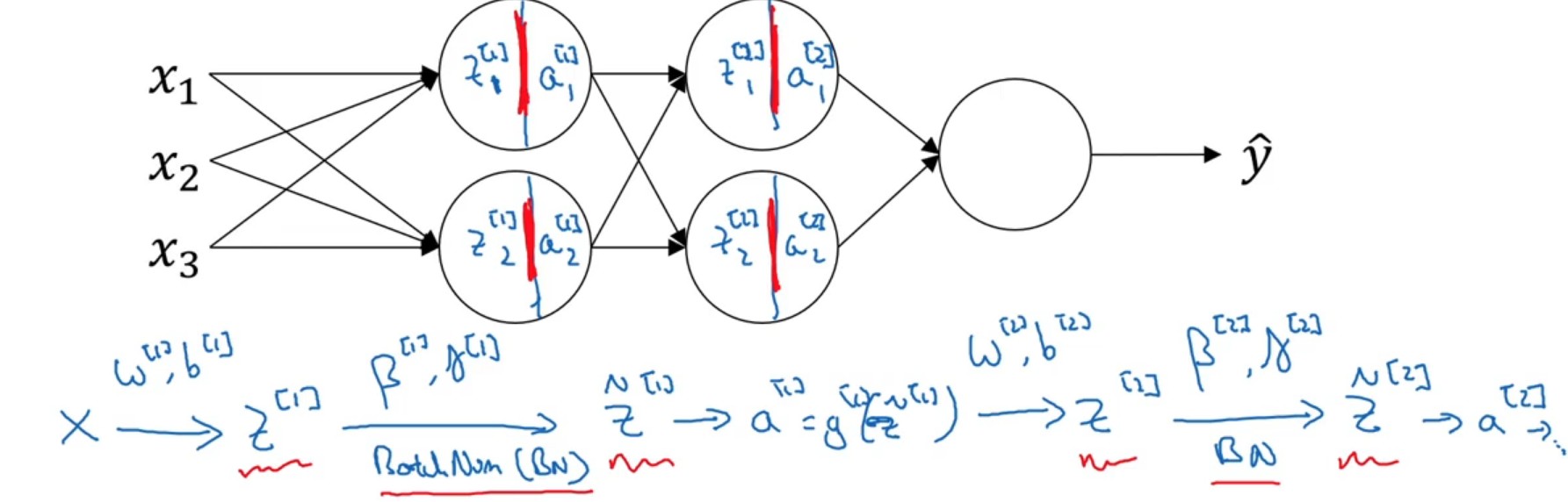
⎩⎨⎧μznorm(i)z^(i)=m1i∑z(i),δ2=m1i∑(z(i)−μ)2=δ2+ϵz(i)−μ=γznorm(i)+β(9.1)
注意:
- 由于对z(i)进行了标准化处理,对于系数b[i]将没有实质意义,可以从网络中去掉;
- 引入两个调节参数β[i],γ[i]。
- 训练集:直接使用min-batch中的所有样本进行计算从而获取。
- 测试集:将训练集中计算得到的 μ{i},δ{i}进行指数平均获取到的μ,δ用于测试计算。
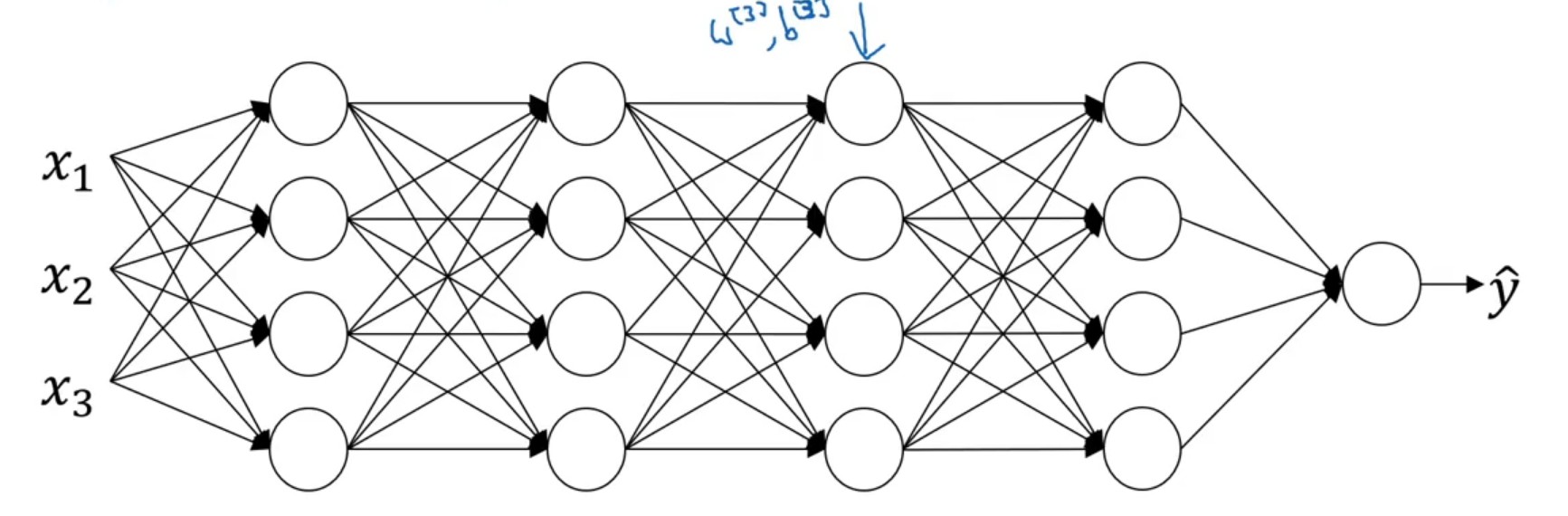
对于第3,4层神经网络而言,它们以a[2]作为样本输入(就认为是样本定值),从而实现结果向y^靠拢。但是从整体网络上来看a[2]受到了第1,2层网络的影响,是变化的。因此,对于a[2]就存在协变量偏移的情况。Batch Norm的作用就是将每一个神经元激活前的样本尽可能都保持在统一的一个分布内。
可以对种数据类型的学习,实现多类型划分。
-
激活函数
输出层的节点数量=类别的数量,并且输出层的激活函数为softmax激活函数。
⎩⎨⎧z[L]ty^=w[L]a[L−1]+b[L]=ez[L]=[∑titi](10.1)
其中:
y^各个输出量的总和为1。输出结果就是样本在各个分类所占的概率。
-
损失函数
L(y^,y)=−i∑Cyilogy^i(10.2)
-
目标函数
J=m1i∑mL(y^(i),y(i))(10.3)
-
顺序编码
对于结果按照数字顺序分类。
[ABCD][1234]
-
one-hot 编码
A=[1000]B=[0100]C=[0010]D=[0001]
正交化:每次调整的选项最好只影响一个阶段,尽量不要影响其他阶段。
对于模型训练遇到的问题可以分四个阶段:
- 首先,确保训练集的结果能达到human-level
- 扩大模型的规模
- 更换训练方法
- 其次,开发集的结果能够让人接收
- 添加正则
- 增加训练数据量
- 然后,测试集的结果能达到目标
- 更大的训练数据量
- 最后,模型正式使用没问题
- 修改cost Function
- 修改指标
评价指标是在对模型各个阶段的结果进行评价,不是cost function。
评价结果好坏的标准应当体现在最终的一个值上(多个评价指标也要规划成一个指标),方便人做出判断,避免选择综合症。
-
F1 分数(调和评价)
查全率(recall):分辨出的猫的数量 / 猫的总量
查准率(precision):分类正确的量 / 总的样本量
F1=P1+R12(2.1)
-
加权平均
当单一评价指标不能对训练目标进行很好描述时,可以使用 满足(satisfacting metrics)+ 优化(optimizing metrics)。 将所有涉及的指标描述成一个带约束的优化问题,这样就又能形成一个单一的指标。
optimizing metrics : 主要优化的目标。
satisfacing metrics : 其余指标的约束条件。
当前的模型指标产生的结果,偏离了或者不满足正式使用的需求,就得马上更改。
自然感知类问题:就是人类能根据自身经验做出判断的问题。例如:图像识别,语言识别,给人看病。。。
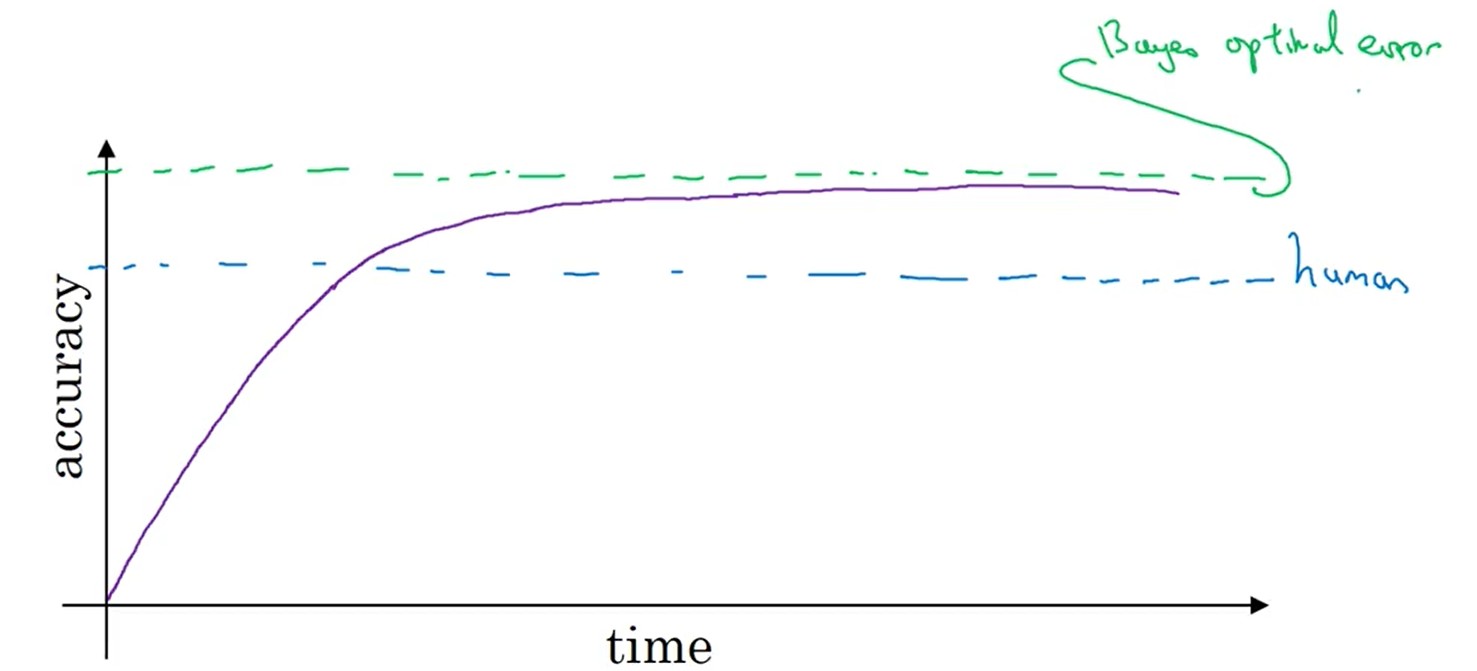
- 在人类的水平(human-level)以下,精度上升很快,当超过人类水平,速度缓慢,逐渐收敛
- 理论上模型能达到的最高精度称之为 贝叶斯最优估计(Bayes optimal error)
- 对于自然感知类问题,人类水平基本上靠近贝叶斯估计,也会直接用人类水平代替贝叶斯估计。
- 对于模型指标低于人类水平,上面所述的方法有效;当超过人类水平,上面所述的方法可能就效果不明显了。
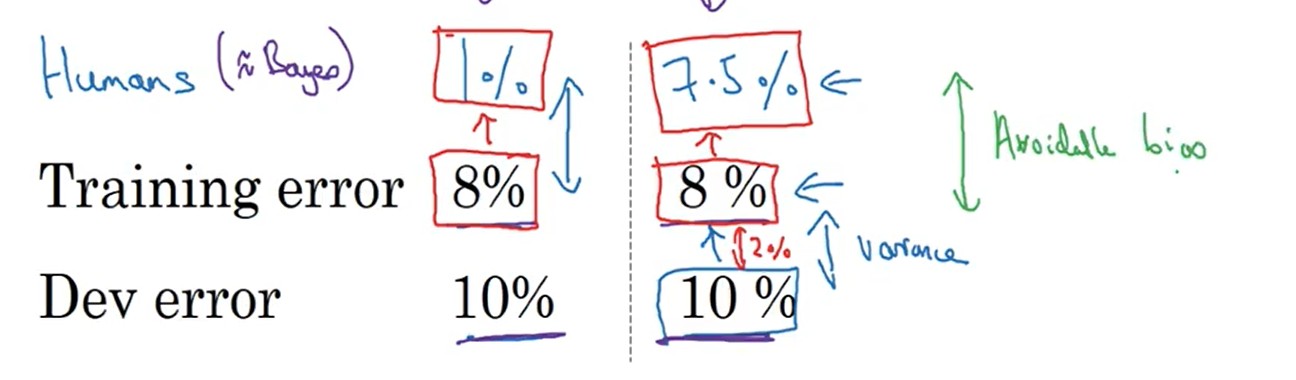
以human-level为基准,来进行偏差和方差分析(分析方法同上一章),然后在采用不同的方法来优化模型训练。
avoidableBias=trainingerror−human−level(3.1)
variance=deverror−trainingerror(3.2)
human-level的取值应当根据具体的问题要求进行选择。
超人类水平问题:模型的表现远远超过超人类水平的问题,例如广告分析,由A到B汽车行驶时间等等。 对于这些问题的表现超出人的表现,主要是因为模型训练涉及到了大量数据的处理。对于这些问题以人类水平作为基础的模型训练方案就不再适用了。
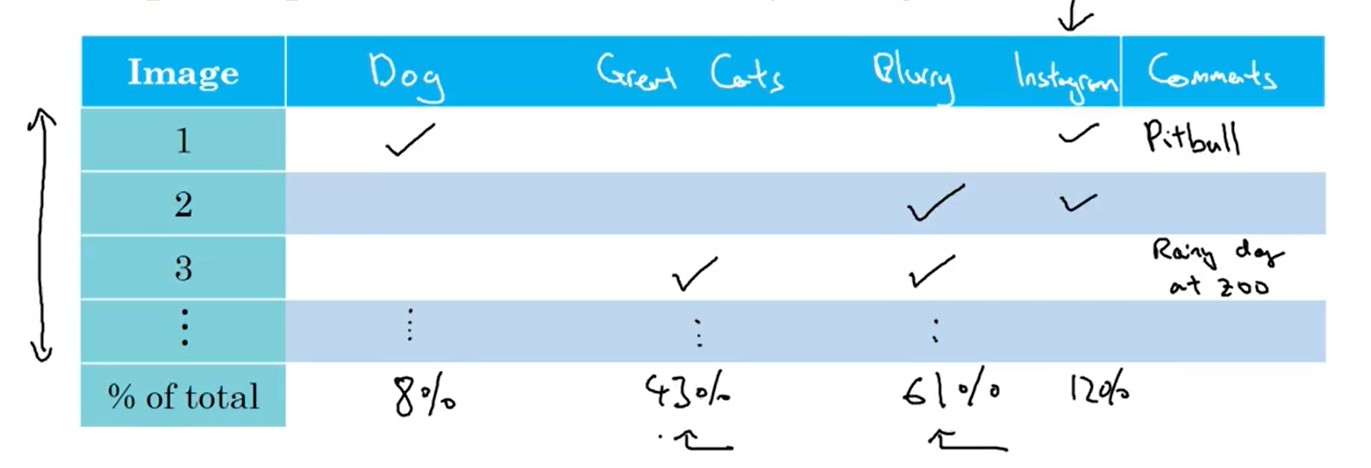
当发现开发集,训练集的指标结果很差劲,可以对 开发集识别错误的样本进行人工分析。
- 将所有猜想的导致错误的原因 列向标出;所有 错误的样本 在横向列出
- 人工逐列分析各个样本错误的原因,并统计
- 最后分析结果,确定优化的方向。
对于收集的样本,如果只是一小部分输入x与输入y之间的对应关系存在问题:
训练集:一般不用修改这些错误,因为训练集样本量大,且算法具有鲁棒性。
开发集:首先进行 错误分析 ,问题样本导致的误差挺大的,就要修正开发集。
当发现问题很严重时,需要就行样本修正:
- 修正后,保证开发集和测试集的分布一致性。
- 也要尽量去检验那些 侥幸计算对的样本
- 修复了开发集和测试集,可能导致与训练集的分布不统一
当模型实际应用的样本太少或者不好获取时,对于样本的分布就不能在采用训练集,开发集,测试集样本均匀分布的方案,应当将实践样本全划分到开发集和测试集,让模型训练是朝着期望走。
数据不匹配问题:由于开发集,测试集同训练集的分布不同,可能会导致训练的模型不能达到我们的预期。 为了观测出 是不是由于这问题导致了模型的不准确 又引入了一个 训练-开发集:该集合的样本分布与训练集相同。

当 dev error 相对于 train-dev error 比较大时,就存在数据不匹配问题。
- 对比训练集样本与实际样本之间的差别
- 增加实际情况的样本数据
- 人工制造实际情况样本数据,尽量增加数据的多样性(可能会导致对单一情况的过拟合)
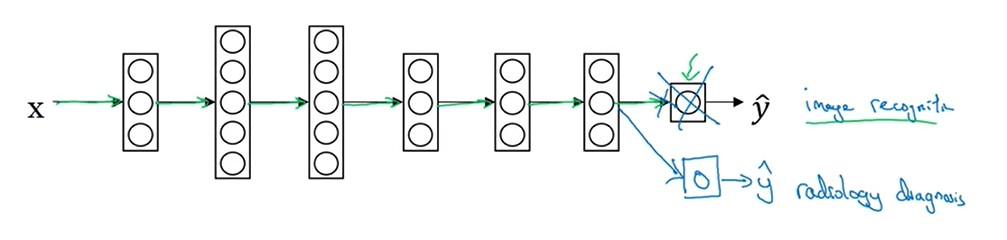
迁移学习:继承其他已经成功的模型,来继续训练当前的模型。
- A模型的x与B模型的x相同
- A模型训练的样本量 相对于 B模型的样本量大的多。
- A模型最开始的几层网络能提升B模型性能的可能性最大:模型从后向前进行修改。
多任务学习:将多个训练目的全放到一个模型中进行训练。 对于无人驾驶而言,可以把识别人,车,路标等功能都集成到一个模型中进行训练。
- 多个任务可以共用一套浅层的网络
- 多个任务分开时,样本量应当能保证大体一致,数量平均
- 当效果不好时,主要因素是网络结构太小
- softmax: 分辨的是什么。多任务学习:分辨的是有什么

直接使用x映射到y,进行神经网络学习,中间不做任何的内容处理,完全的黑箱。
好处:
- 模型完全依赖数据
- 在x -> y的过程中,不用再考虑添加其他处理流程。
坏处:
- 一般需要大量的数据才能出效果
- 人工控制降低
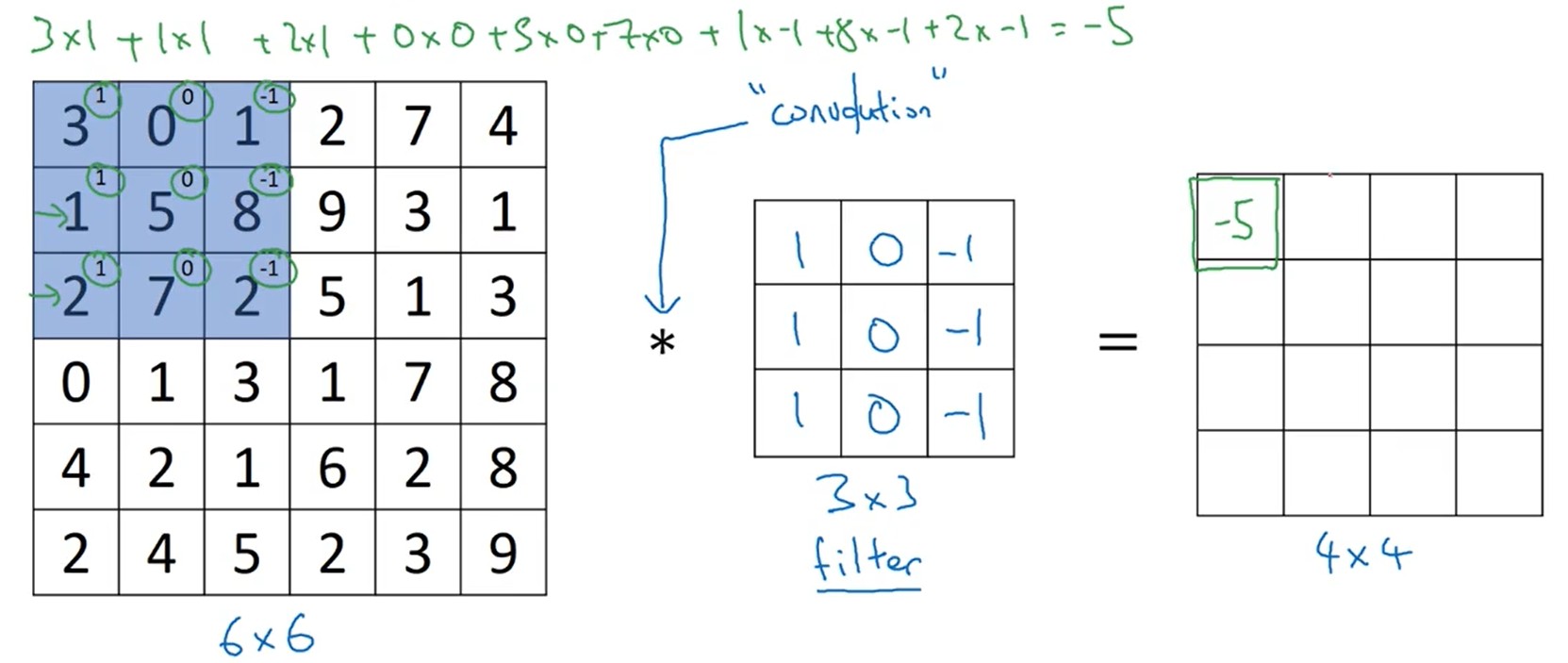
输入图片(6x6)与过滤器(3x3)进行矩阵的卷积计算,得到输出(4x4)。
输出纬度的计算:
no=⌊sni+2p−f+1⌋(1.1)
f : 过滤器的纬度
p : 输入图片填充的像素
s : 过滤器在输入图像上移动的步长
当步长s不为1时,可能导致过滤器越界,所以使用floor进行向下取整。
在图像识别中所说的“卷积”和实际定义有一点小差别,图像识别省略了:对过滤器进行右对角线的翻转(对结果没啥影响,没必要算了)。图像识别中的卷积准确应当称之为:cross-correlation。
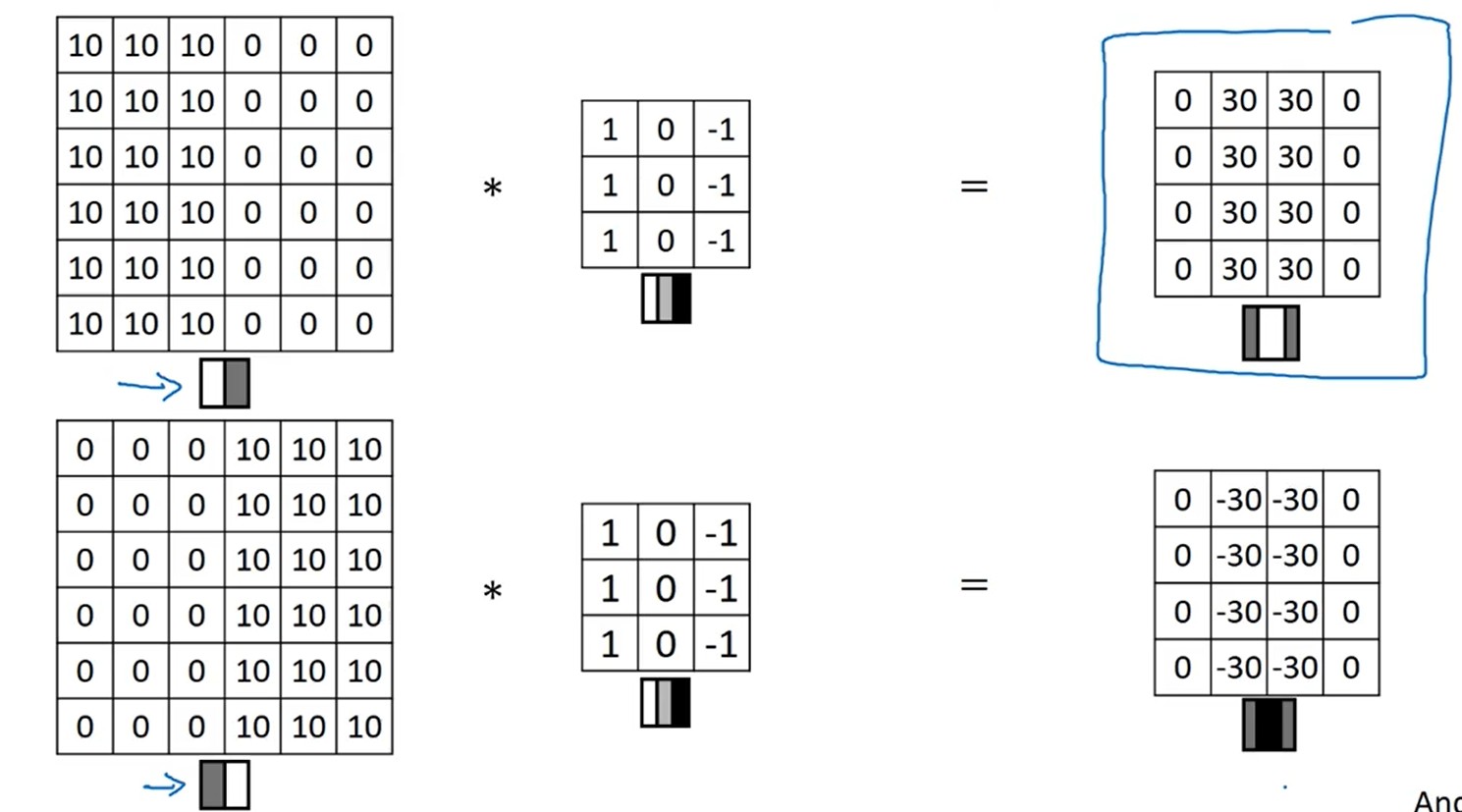
定义一个竖向的过滤器,就能实现对竖向的边缘进行监测;同样定义一个横向的过滤器,就能对一个横向的边缘进行监测。对于过滤器的值,可以自定义,不用完全是-1或者1。因此,卷积神经网络就直接将过滤器中的所有系数,都设置为w系数。
进行卷积计算后,原来的图像会被缩小,为了规避这个问题,可以将原来的图像的进行边缘扩充像素。根据公式(1.1)就能将卷积后的图像尺寸保持得和输入图像一样大。
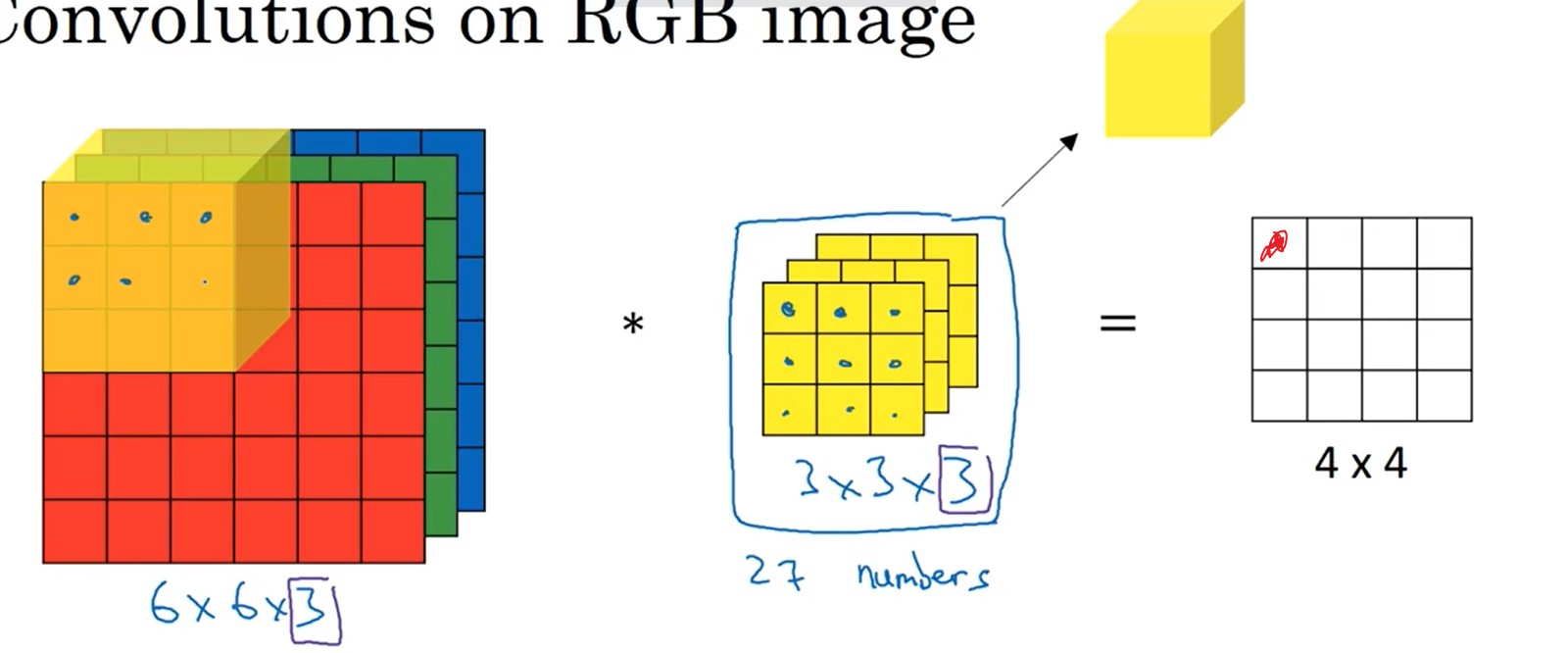
输入的通道数和过滤器的通道数相同,才能进行计算。
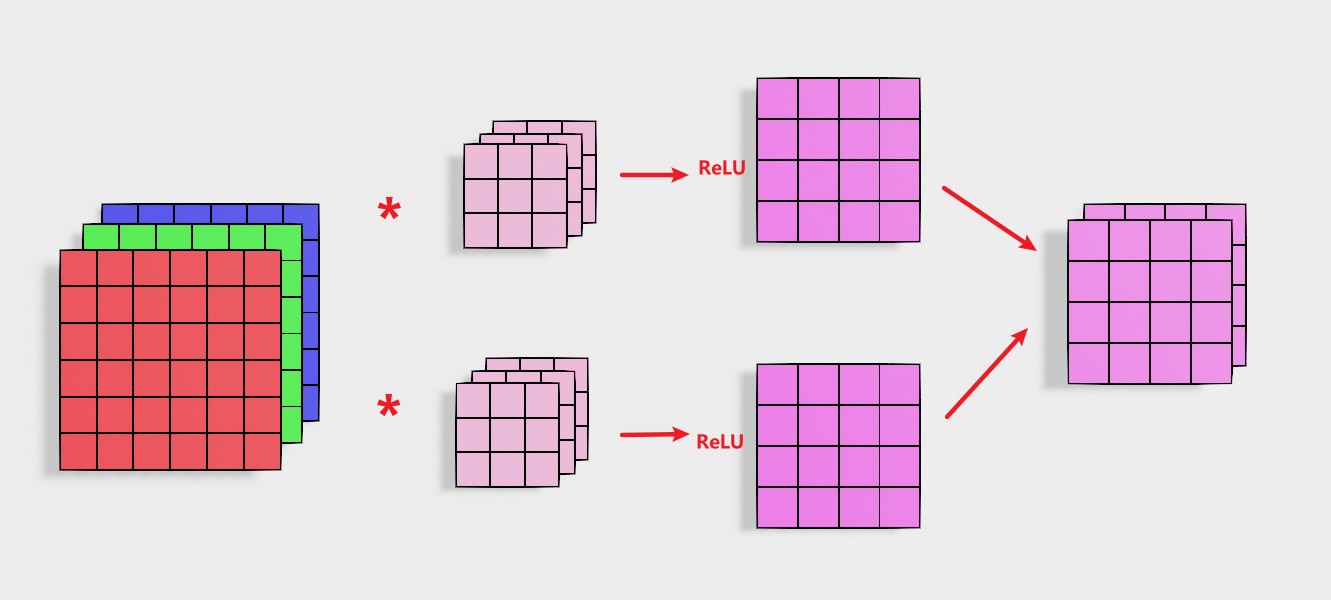
一张图像通过两个滤波器,计算得到两层;在将两层送入激活函数;最后将两个层重合得到输出。
a[l]=active(input∗filter+bias)(5.1)
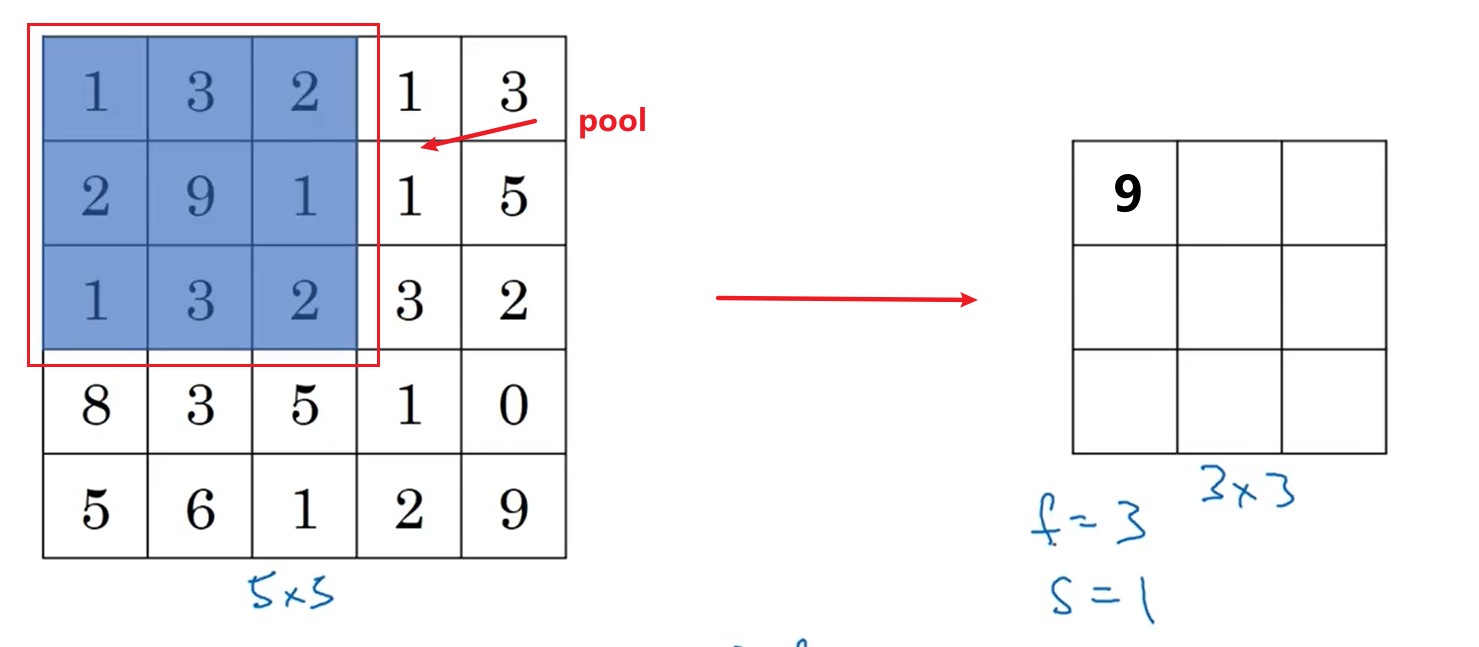
不同于卷积,池化的作用是将原来的像素,按照块操作,进行压缩处理。 根据压缩数据方式的不同分为:1)max pooling,区域内的最大值;2)average pooling,区域求平均值。
no=⌊sni−f+1⌋(6.1)
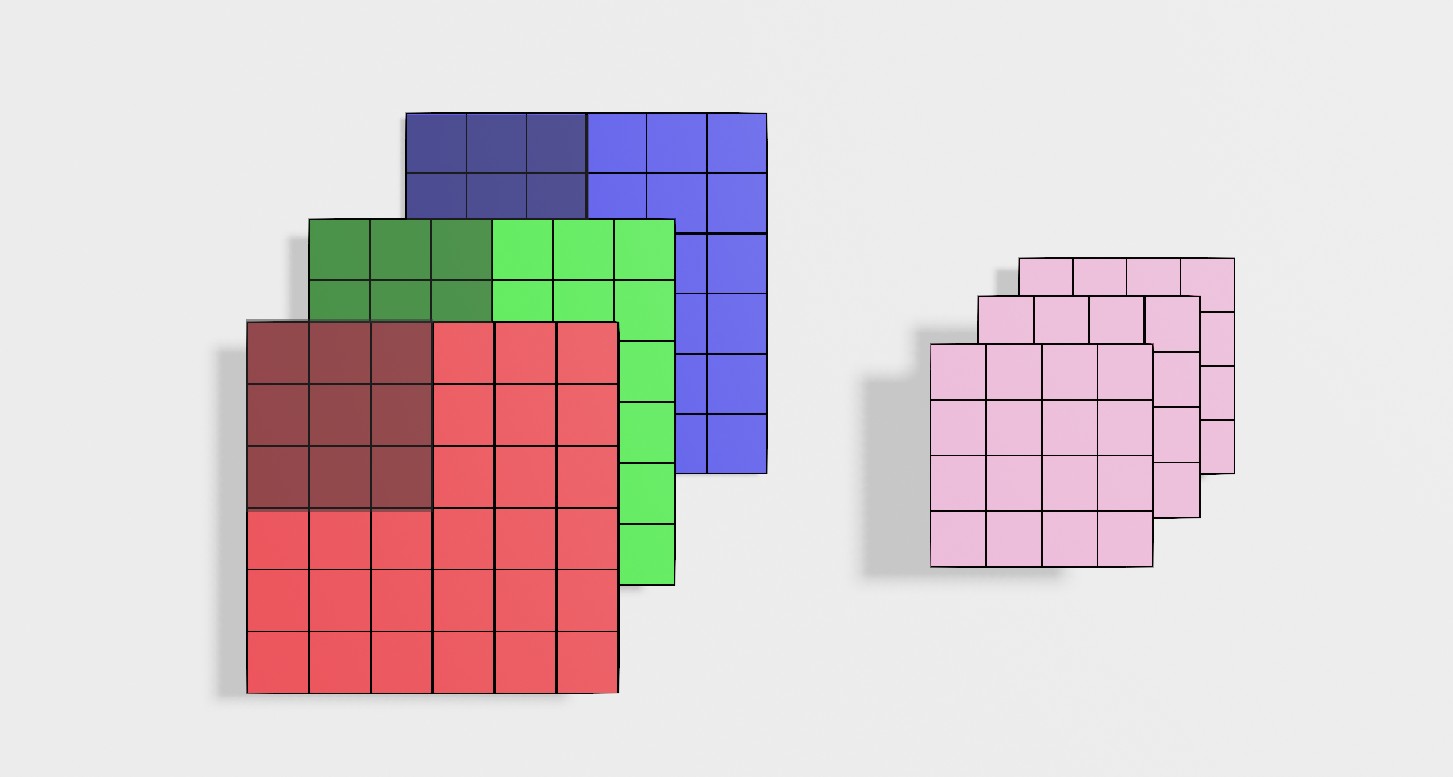
- 对于pooling的计算,是每一个通道进行一次计算,输出结果通道数不改变。
- pooling涉及的超参数,训练集训练时就是为常量。
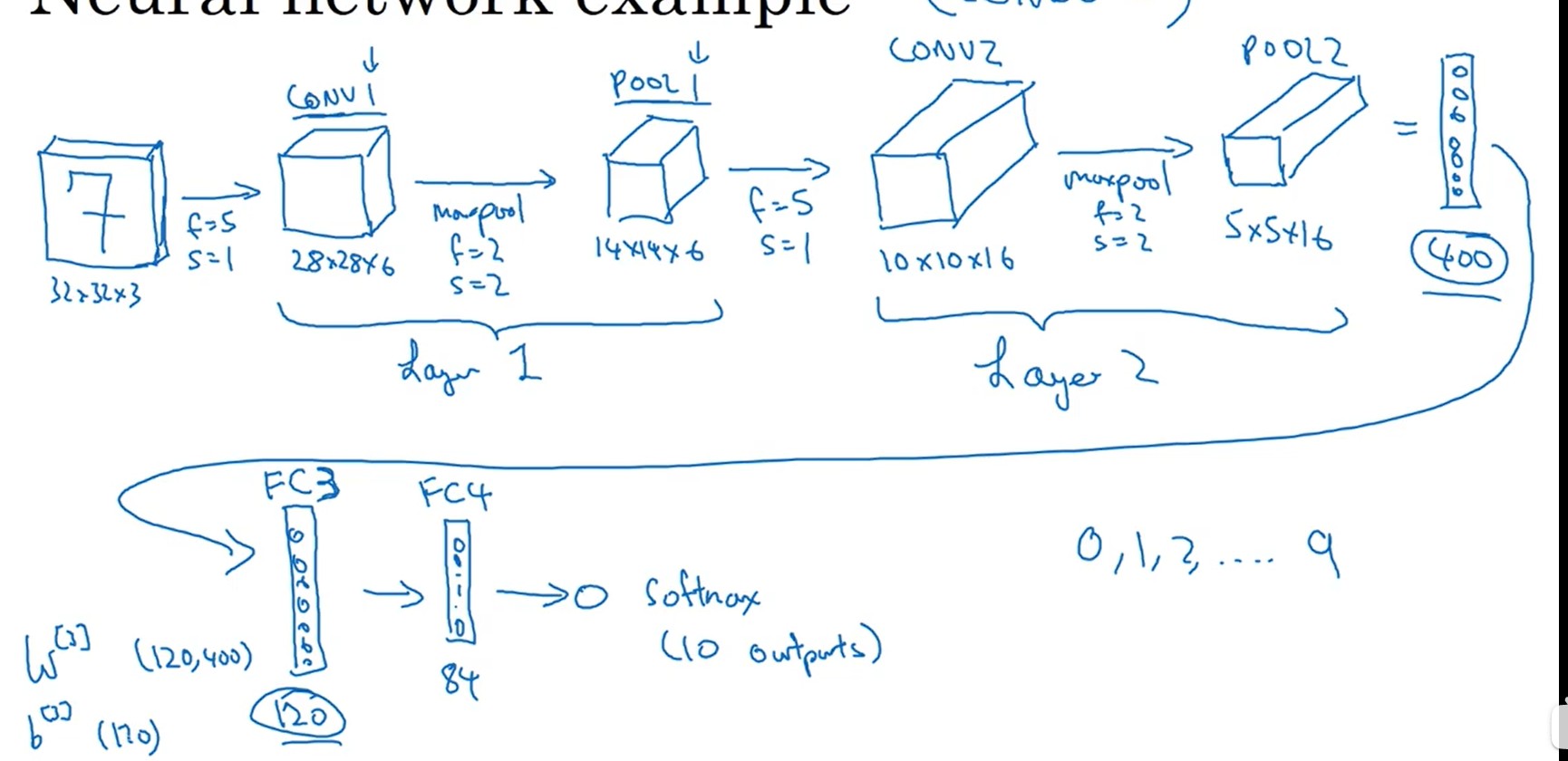
- 图像刚输入的时候,靠卷积和池化降低参数数量。
- 输出就是靠全连接网络(BP网络)和分类器获取估计结果。
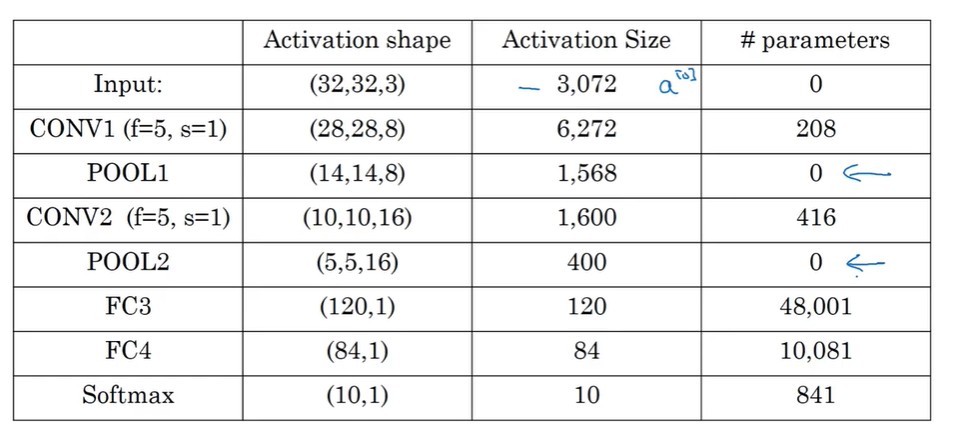
与普通神经网络相比,卷积网络大大降低了超参数的量,实现了对图像像素的压缩和特征提取。
- parameter sharing:用于一次过滤的过滤器都是一样的,数据处理过程统一,也降低了超参数的量。
- sparsity of connection:每个像素只能影响局部的结果,符合常规认知。
-
单样本表示
x为n维的输入;y为[是|否]。
(x,y)x∈Rn,y∈0,1(1)
x为nx维的输入;y为ny维度输出。
(x,y)x∈Rnx,y∈Rny(2)
-
多样本表示
m个nx维的X
X=⎣⎡∣∣x(1)∣∣∣∣x(2)∣∣⋯⋯⋯∣∣x(m)∣∣⎦⎤(3)
m个ny维的Y
Y=[y(1)y(2)⋯y(m)](4)
-
上标(i)
与第i个样本有关: z(i)=wTx(i)+b
-
上标[i]
与第i层神经元有关:w[i],b[i]
-
上标{i}
某个集合的子集:x=[x1,x2,⋯,xm],x{1}=[x1,x2]
-
导数 dvar
表示目标J关于变量var的导数
dvar=dvardJ(5)
-
i层的输出l
a: active;表示激活函数的输出。
a[i](6)
-
卷积神经网络
滤波器纬度:f[l]
填充数:p[l]
步长:s[l]
滤波器的数量:nc[l]
输出:nH[l]×nW[l]×nc[l]
当前滤波器的规格:f[l]×f[l]×nc[l−1], 当前滤波器的深度就是上一层的滤波器个数