《阿哈!算法》
-
快速排序: quick sort
-
队列: queue
-
栈:stack
可以用来处理镜像对称问题
-
链表:link, simulation link
- 深度搜索:depth first search
void search(location){ // 期望的结束条件 if(){ return; } // 尝试所有可能性,向后移动 for(){ // 移动到下一步 loctation = location + 1; search(location); // 从 后面 回退回来,复原状态 location = location - 1; } // 隐含的结束条件:**不能向后移动时,回退** return ; }
-
广度搜索:breadth first search
void search(location){ // 尝试**当前点**对应的所有可能性; for(){ // 将移动的一步入对 queue.push(location + 1); // 找到目的时,就结束递归 if(){ return; } } // 将**当前点**出队 queue.pull(); // 队列为空。没有找到目标,结束递归 if(queue.head == queue.tail){ return; } // 以队首为**起始点**继续处理 search(queue.head) }
-
漫水填充:floodfill
基于 深度搜索 或者 广度搜索
-
树
- 与图的区别:不包含回路的的连通无向图
- 树的特点
- 任意两个节点有且仅有一条通路
- n个节点对应(n - 1)条边
- 二叉树:一个节点最多只有两个子节点
- 满二叉树:叶节点的深度都是h;除叶节点外,所有节点都有两个子节点;深度为h,节点为
- 完全二叉树:叶节点的深度都是h;叶节点的右边补上几个节点才能形成满二叉树
- 满二叉树与完全二叉树特点:
- 父节点的编号为k,子左节点编号为2k,子右节点的编号为2k+1
- 子节点的编号为x,父节点的编号为
- 从上往下最后一个父节点的编号为
-
堆:数据存储为完全二叉树;根节点为最大值或最小值。
- 存储数据使用 list 容器,代替数组。方便动态删除和扩充
- 数组的起始下标应为1,使用0会导致乘法计算下标出问题
- 堆排序:一直删除root节点,更新root节点,直到堆为空,就完成排序。
《图解算法》
-
二分法查找:只能用于查找有序的数据
-
在有序序列中找到指定值: dichotomizing search
search(int low,int high){ // 序列中不存在:由于low向左移动,high向右移动。所以找不到的情况就是 low > high if(low > high){ return "not found"; } // 中间位置: 奇数时,向下取整 int mid = (low + high) / 2; // 小于 中间 的值 if(target < datas[mid]){ high = high - 1; } // 大于 中间 的值 if(target > datas[mid]){ low = low + 1; } // 等于 中间 的值 if(target == datas[mid]){ return mid; } // 下一次查找 search(low,high); }
-
在有序序列中找到给定值的邻近区间: dichotomizing block
void findBlock(int left,int right){ if ((right - left) == 1) { // left 对应的索引就是区间左边,right 对应的索引就是区间的右边 return; } mid = (right + left) / 2; // 小于等于中间值 if (current <= datas[mid]) { right = mid ; } // 大于中间值 if (current > datas[mid]) { left = mid; } // 进行下一次寻找 findBlock(left,right); }
-
-
大O表示法:描述的是运算时间的增量,而非运算时间
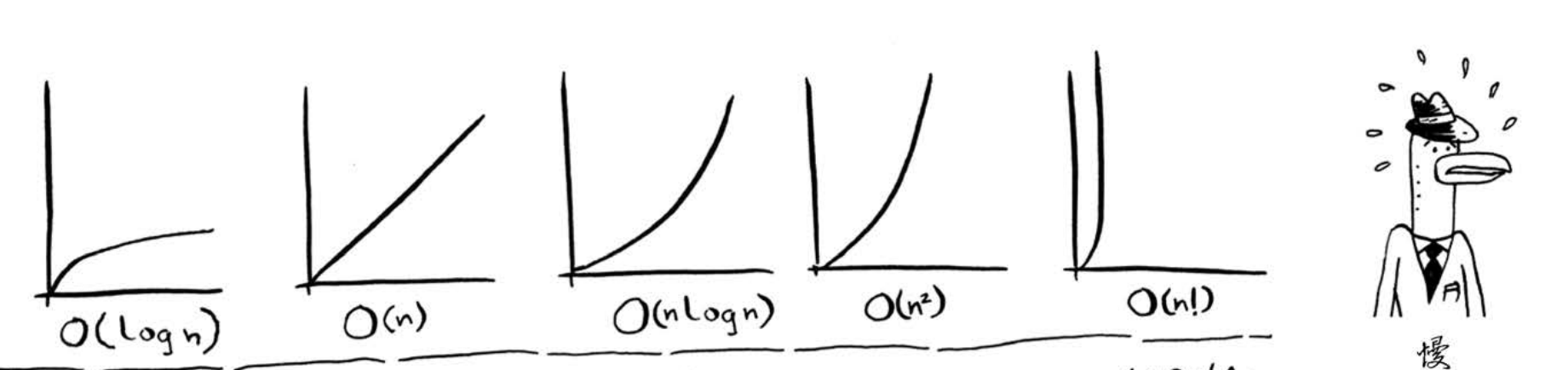
- 对一些算法的运算速度比较时,大O表示法中的省略项,例如(c * n)中的c,将起到主导作用。
- 对于递归的表示:O(调用栈的高度 * 一层中的O())
- 递归的一般形式: (当下该如何做,下一步如何做则重复 -- 《啊哈!算法》)
T function(T input){ // 基线条件 if(){ return ; } // 递归条件 ... function(nextInput); ... return; }
-
图的储存方式:
-
- 书中描述错误:
狄克斯特拉算法不能用于环向图,无向图 - 狄克斯特拉算法不能用于 负边权重查询
- 狄克斯特拉算法用于带权重图的短路径搜索
- 书中描述错误:
-
- 采用当前最优的方案
- 重复第 1;直到操作结束
-
NP完全问题:可以使用贪婪算法进行解决
- 集合覆盖问题
- 旅行商问题
-
-
- 动态规划
- 问题的最优结构的描述:
- 递推式获取:
- 初始值指定
- 求解递推式得到:
- 根据获取最终结果
- 动态规划
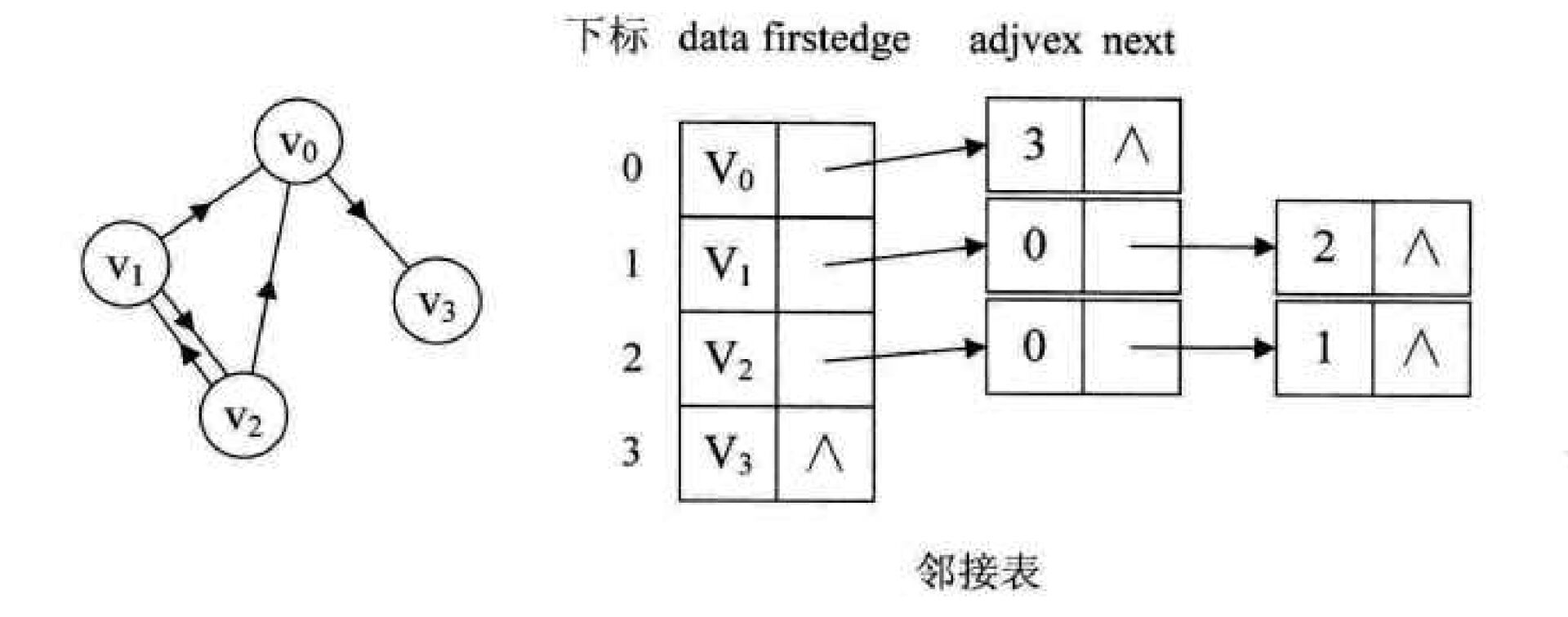
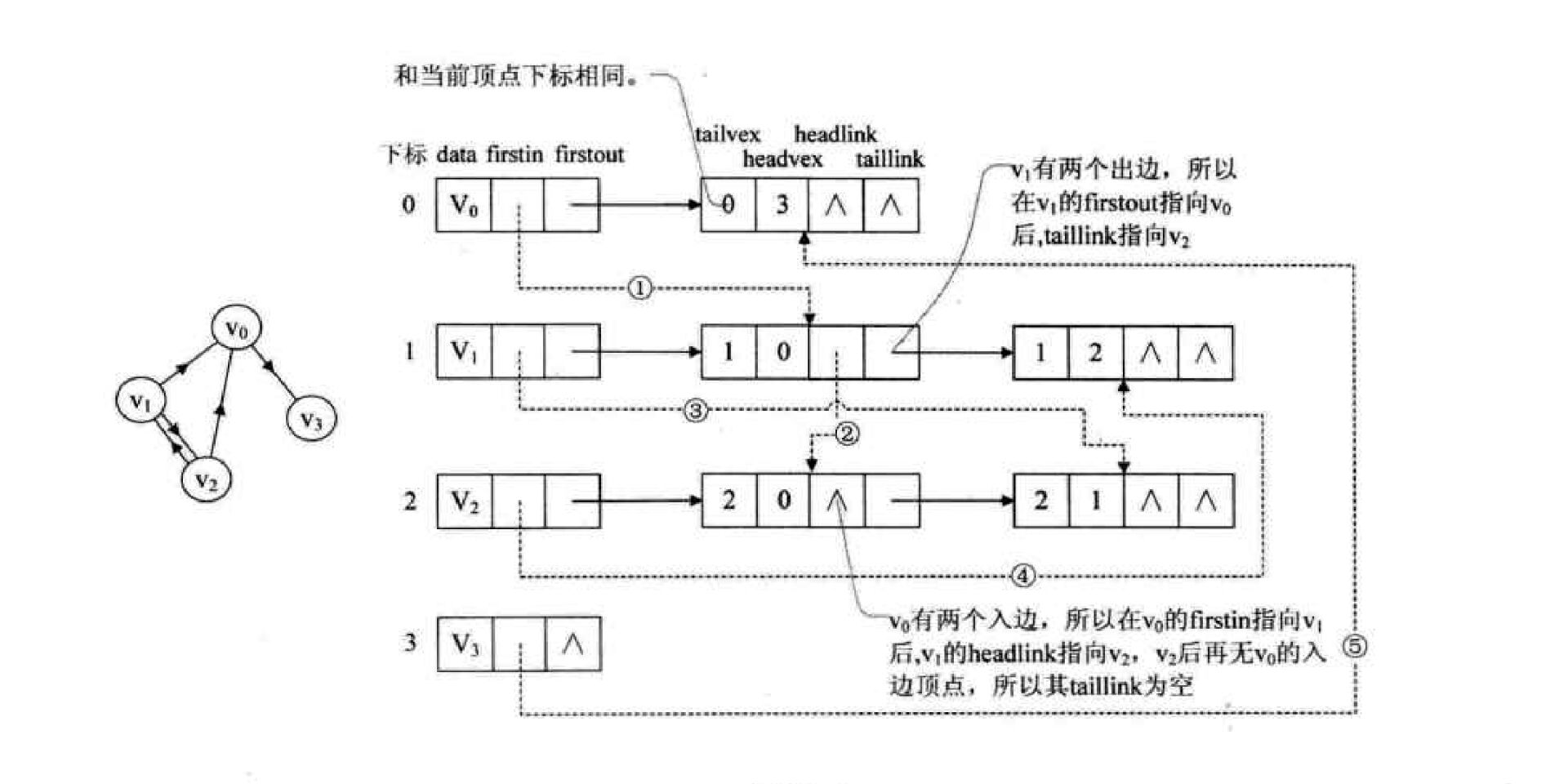
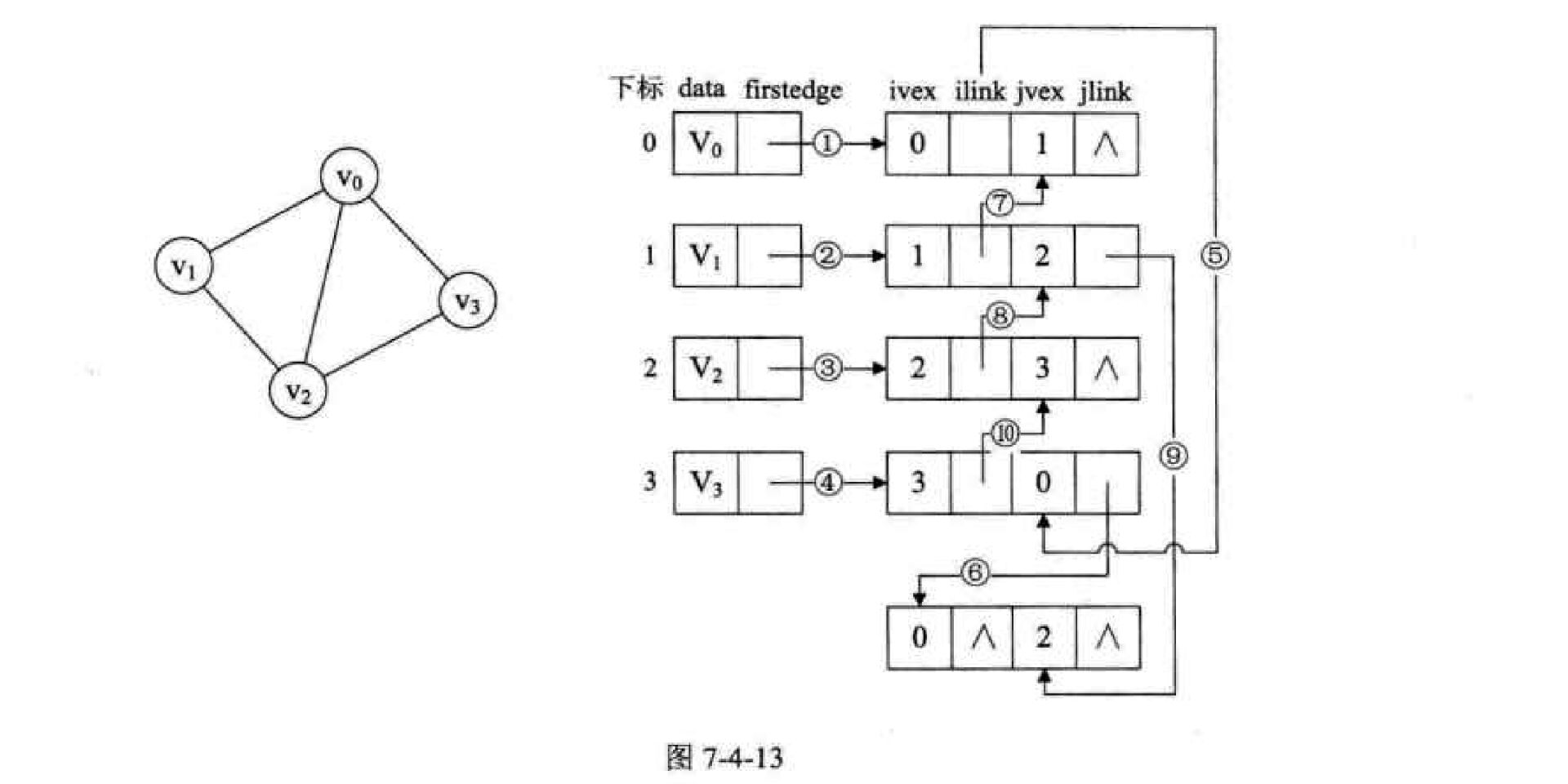
《大话数据结构》
-
链表栈:link stack
-
四则表达式运算:四则表达式运算
- 中缀表达式转后缀表达式

- 后缀表达式运算
- 中缀表达式转后缀表达式
-
循环队列:loop queue
-
树的存储方法
对于同一层的节点,顺序默认为从左到右
-
双亲表示法
每一个树节点由父节点的索引下标和数据两部分组成;然后将所有节点存储在数组中。(还可以添加一个右兄弟索引;第一个孩子索引。)struct Node{ // 父亲节点的下标 int parent; // 第一个孩子 int firstChild; // 右边的兄弟 int rightBrother; // 数据 data; } class tree{ // 定义树 Node trees[N]; }
-
孩子表示法
把一个节点的子节点索引全部放一个链表里面。父节点用数组进行存储。
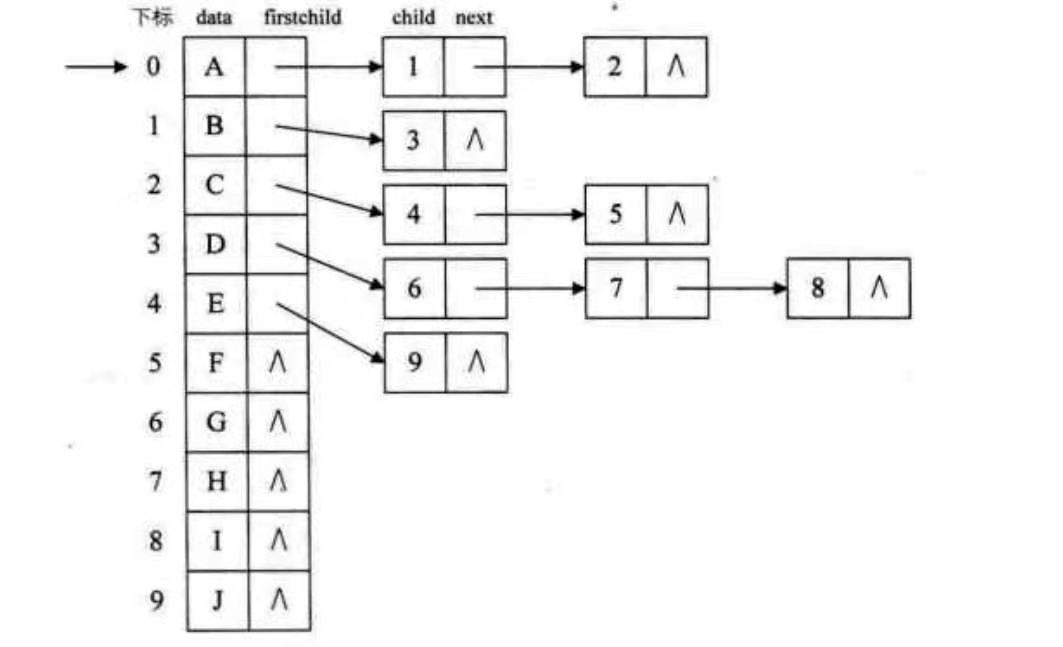
struct childNode{ // 当前孩子的下标 int index; // 下一个孩子的指针 childNode * next; } struct Node{ // 数据 data; // 父节点 int parentIndex; // 第一个孩子 childNode * firstChild; } class tree{ // 树的定义 Node trees[N]; }
-
孩子兄弟表示法(二叉链表同理)
由于同一层节点默认是从左到右排列,所以对于一个节点来说其右兄弟是唯一确定的;第一个孩子也是唯一确定的。所有节点就使用链表进行存储。并且树也被改写成了一个二叉树的形式。
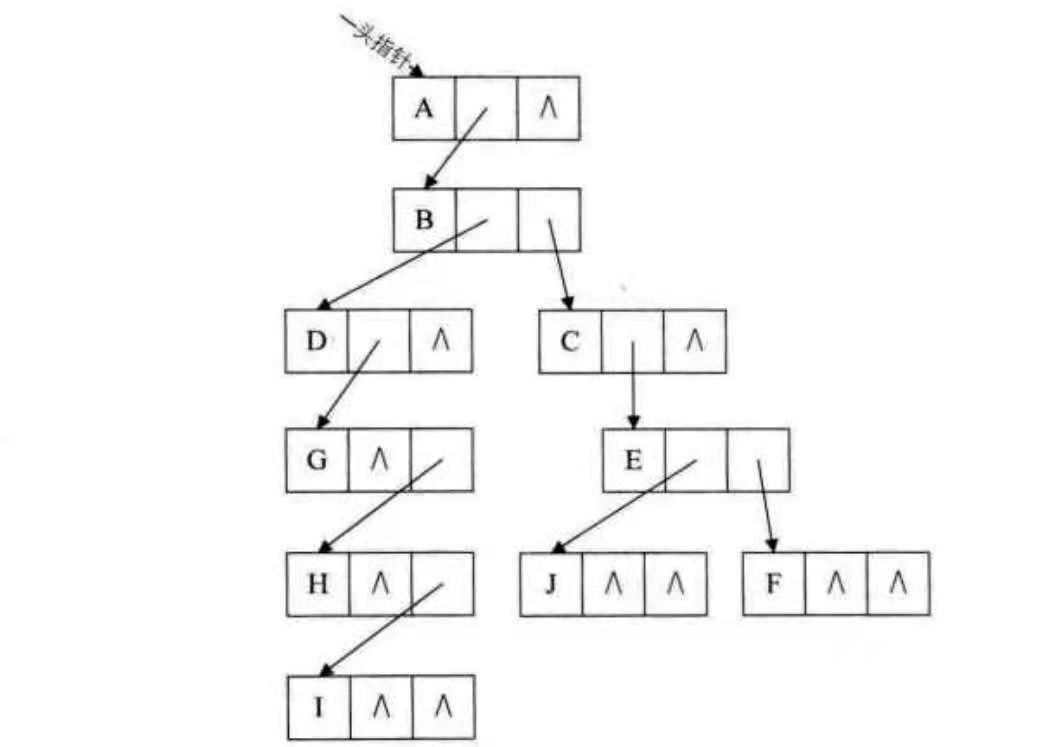
struct Node{ // 数据 data; // 第一个孩子节点 Node * firstChild; // 右兄弟的节点 Node * rightBrother; // 父节点 Node * parent; } class tree{ Node rootNode; }
-
数组
完全二叉树
-
-
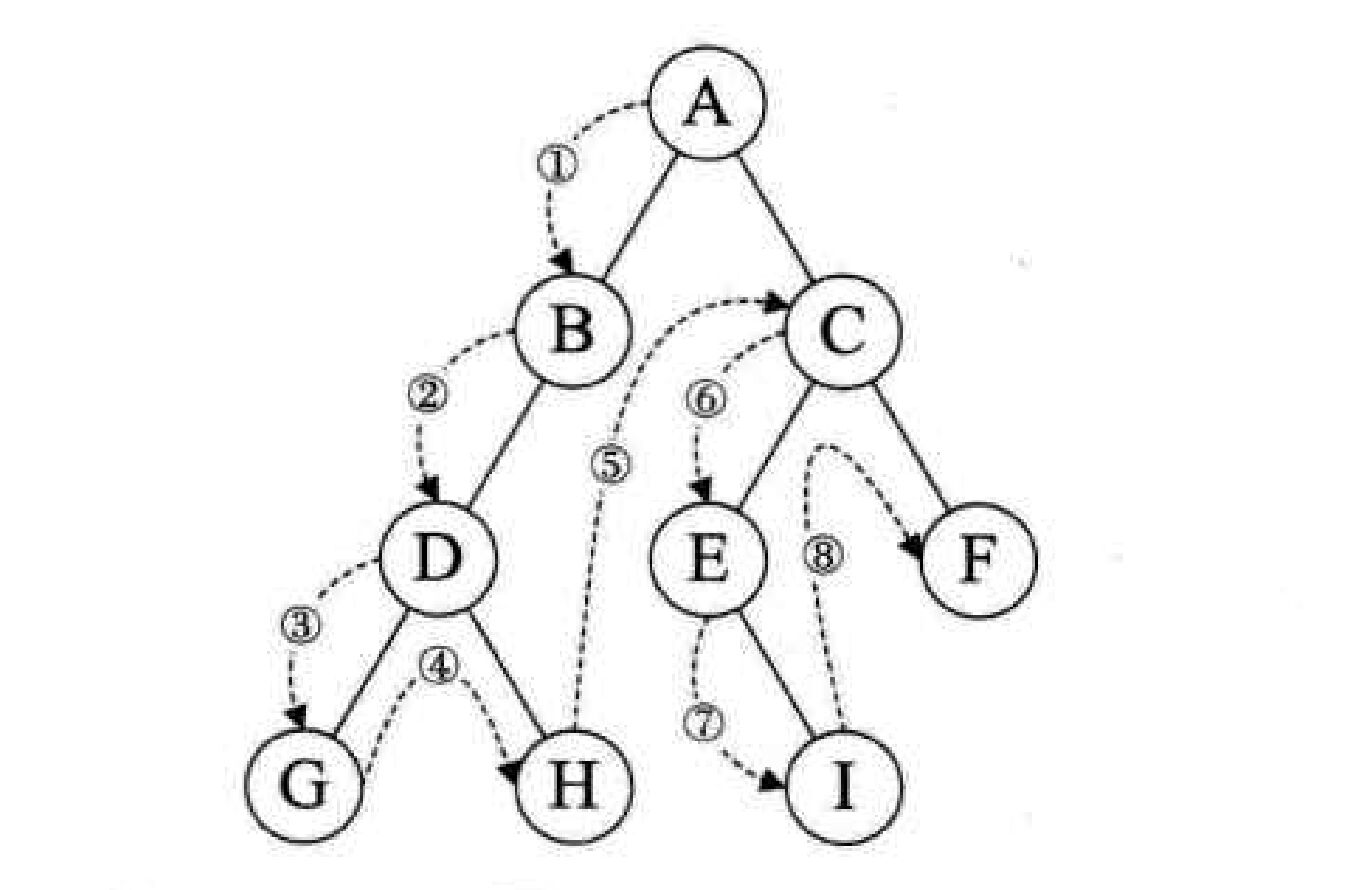
二叉树的遍历:三种遍历方式,就是处理数据的位置不同
遍历的总体框架为深度搜索法。以下描述中的Null表示节点遍历过或者该节点为空先输出当前节点;然后遍历左子节点;左子节点到底为Null后,遍历右子节点。右子节点都为Null,就回退。
void traversal(Node T){ if(T == Null){ return; } // 遍历所有可能性 print(T.data); traversal(T.leftChild); traversal(T.rightChild); }
先遍历左子节点;左子节点到底为Null后,然后输出当前节点;遍历右子节点。右子节点都为Null,就回退。
void traversal(Node T){ if(T == Null){ return; } // 遍历所有可能性 traversal(T.leftChild); print(T.data); traversal(T.rightChild); }
先遍历左子节点;左子节点到底为Null后;遍历右子节点,右子节点为Null后;然后输出当前节点。右子节点都为Null,就回退。
void traversal(Node T){ if(T == Null){ return; } // 遍历所有可能性 traversal(T.leftChild); traversal(T.rightChild); print(T.data); }
-
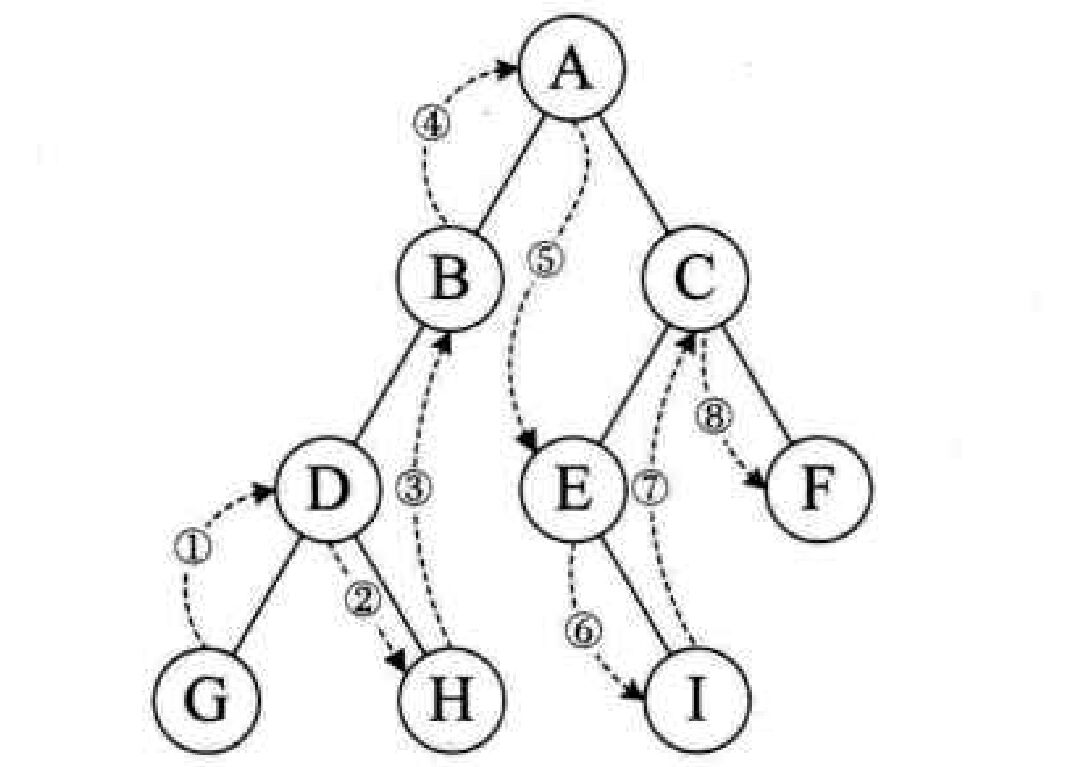
二叉树的反向遍历:由遍历序列到二叉树结构
- 首先将遍历序列扩展:叶子节点添加左右为“#”的子节点;
- 选择一种遍历序列的方案,生成扩展的遍历序列;
- 以遍历序列为输入,用序列生成的遍历序列方案进行二叉树生成。
-
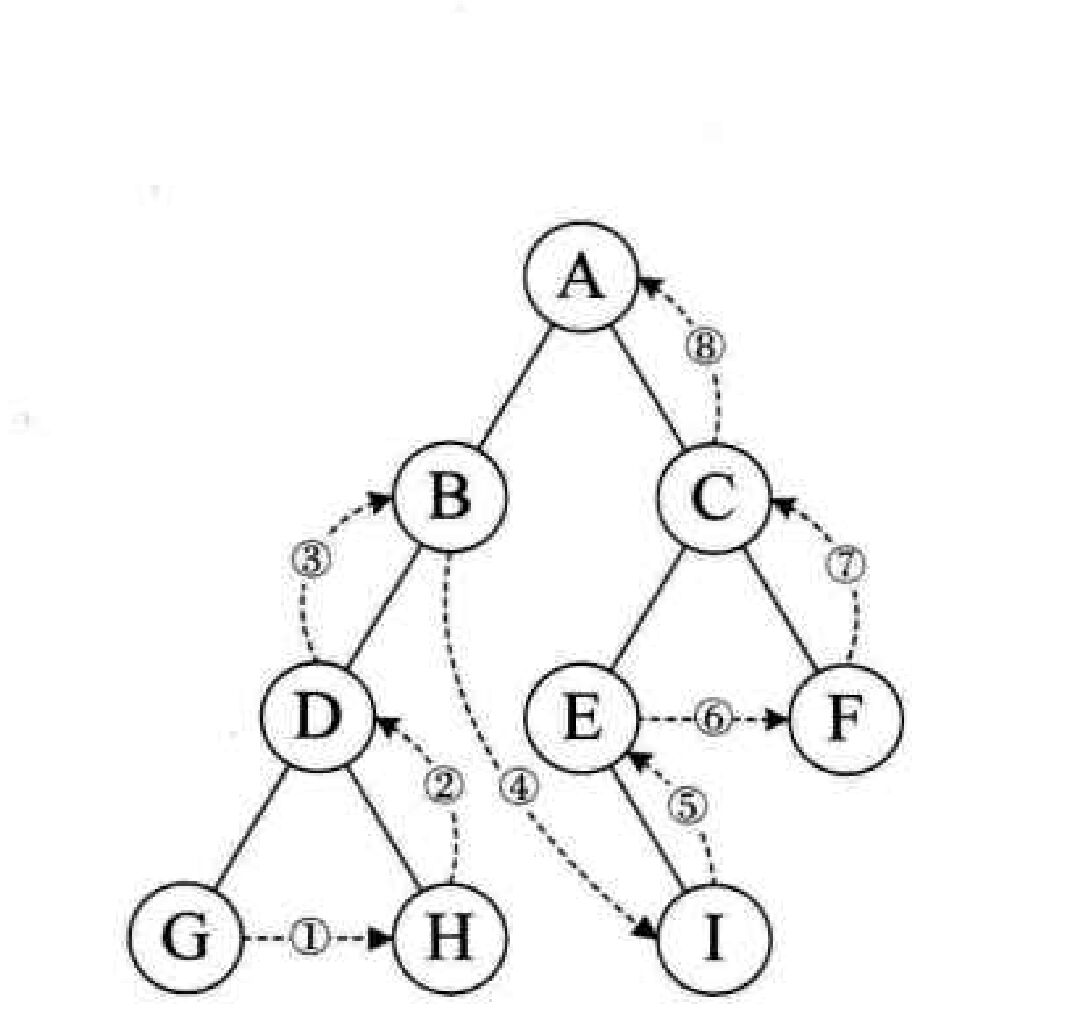
线索二叉树:在链式二叉树中,利用叶子节点空余的空间将最终的遍历序列从二叉树转为双链的形式。
-
树,森林与二叉树的相互转换
-
树转二叉树
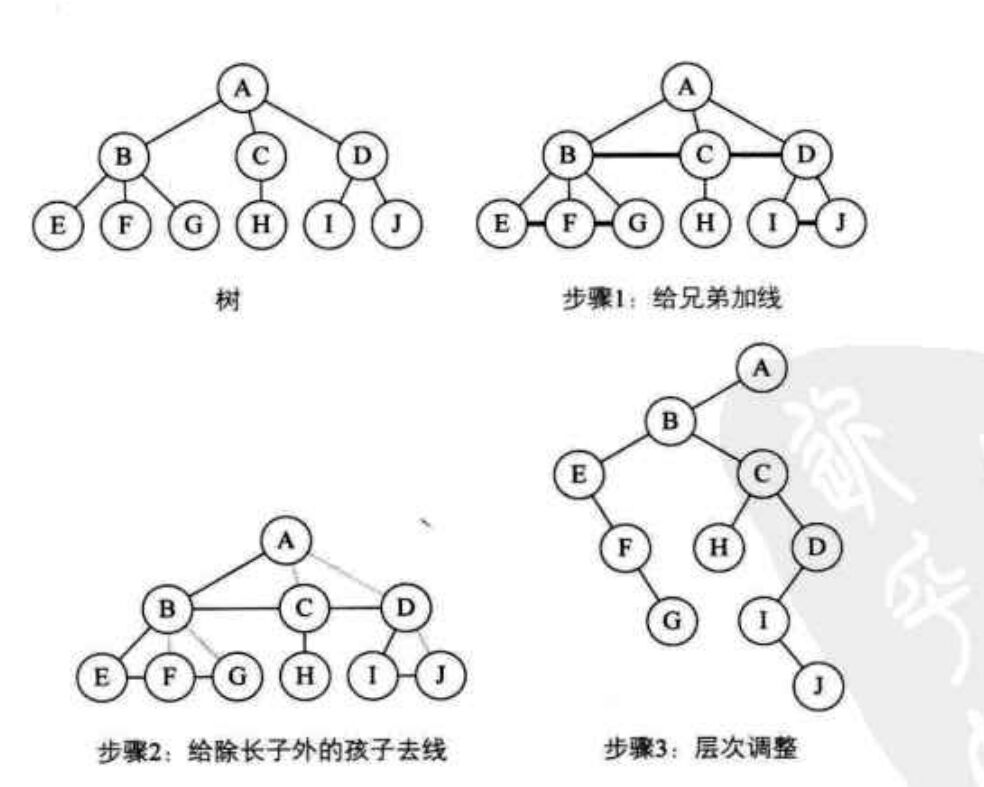
左子节点为第一个孩子
右子节点为兄弟 -
森林转二叉树
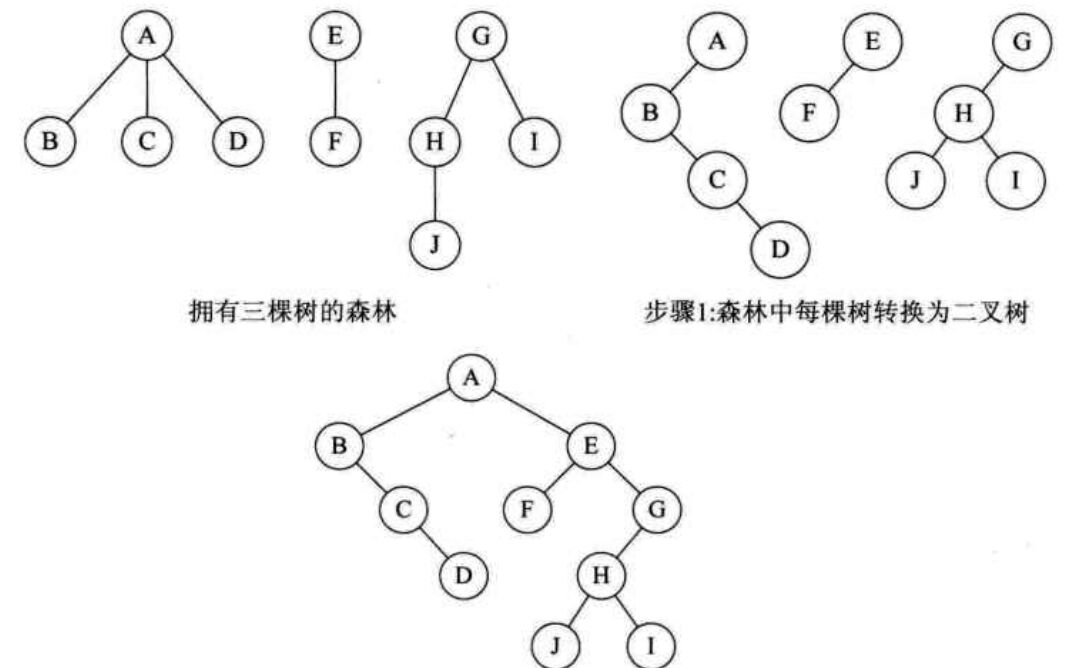
将每棵树的根节点,同(1.)中,当兄弟连接
-
-
最小生成树
- 生成树:是原图的一个子图;包含所有节点;n-1条边。
- 最小生成树:网图(权值图)权值加和最小的生成树。
-
- 贪婪算法
- 2分钟搞懂最小生成树prim算法